 技術
技術 IDEA-CCNL/Erlangshen-TCBert-110M-Sentence-Embedding-Chinese
紹介 Brief Introduction110Mパラメータの文章表現Topic Classification BERT (TCBert)。110Mパラメータを持つTCBertは、中国語の話題分類タスクのための文章表現に事前トレーニングされ...
技術  技術
技術 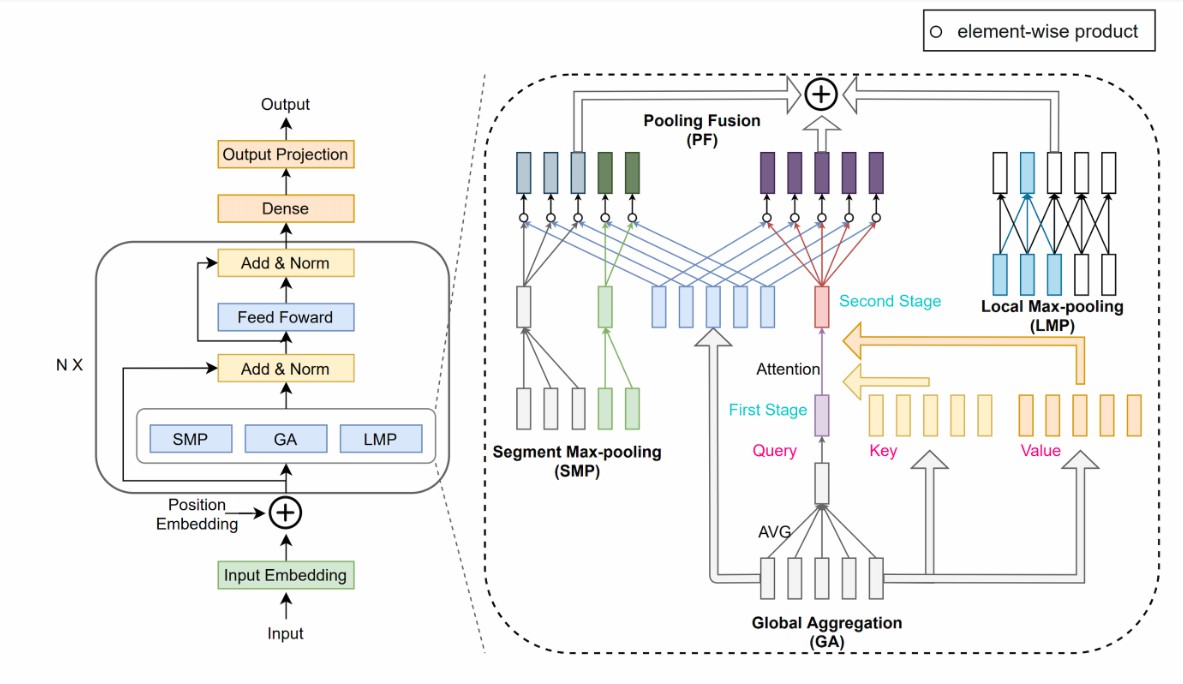 技術
技術  技術
技術  技術
技術 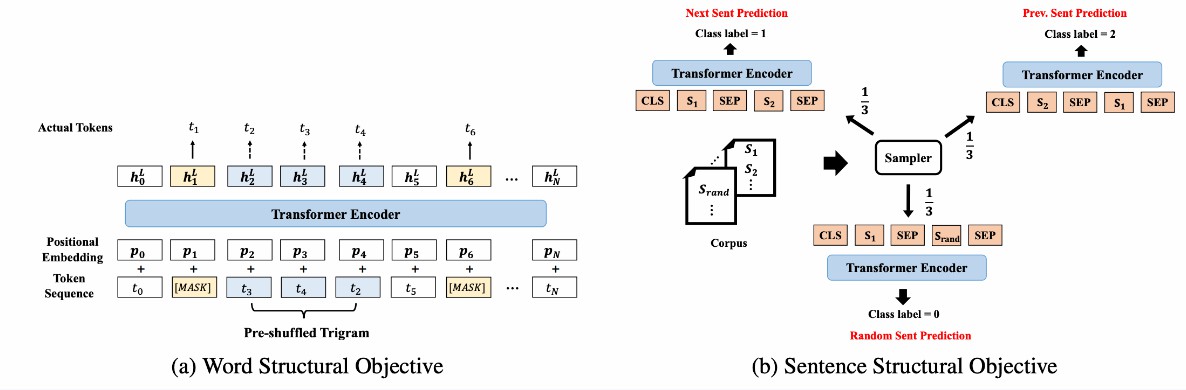 技術
技術  技術
技術 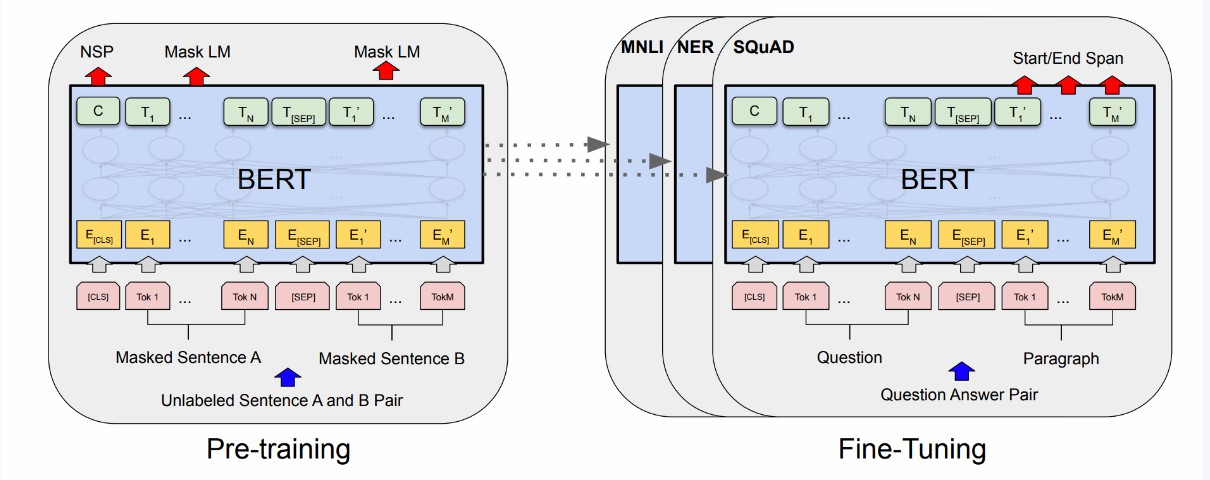 技術
技術 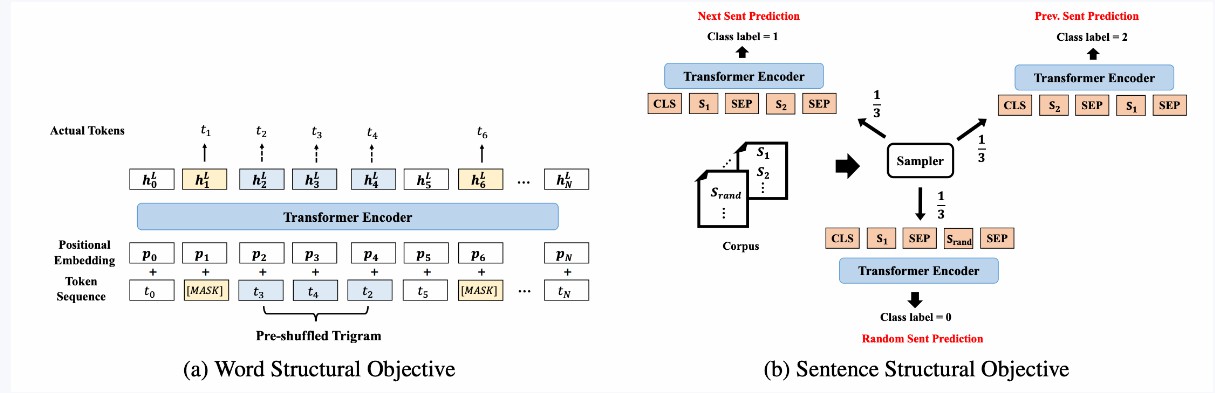 技術
技術  技術
技術