このモデルはPoNetモデル構造を使用し、マスク付き言語モデル(Masked Language Modeling、MLM)と文章構造目的(Sentence Structural Objective、SSO)の事前トレーニングタスクを通じて中国語Wikipediaデータに基づいて事前トレーニングされています。完形填空タスクに使用されるだけでなく、下游の自然言語理解タスクでfine-tuneして使用する初期化モデルとしても使用できます。
モデル説明 PoNetは線形复杂度(O(N))を持つ計算モデルで、Transformerモデルの自己注意メカニズムをプーリングネットワークに置き換えて文章の単語を混合します。具体的には、ローカル、セグメント、グローバルの3つの粒度でプーリングネットワークを含み、文脈情報を捕捉します。その構造は下記の図のように示されています。
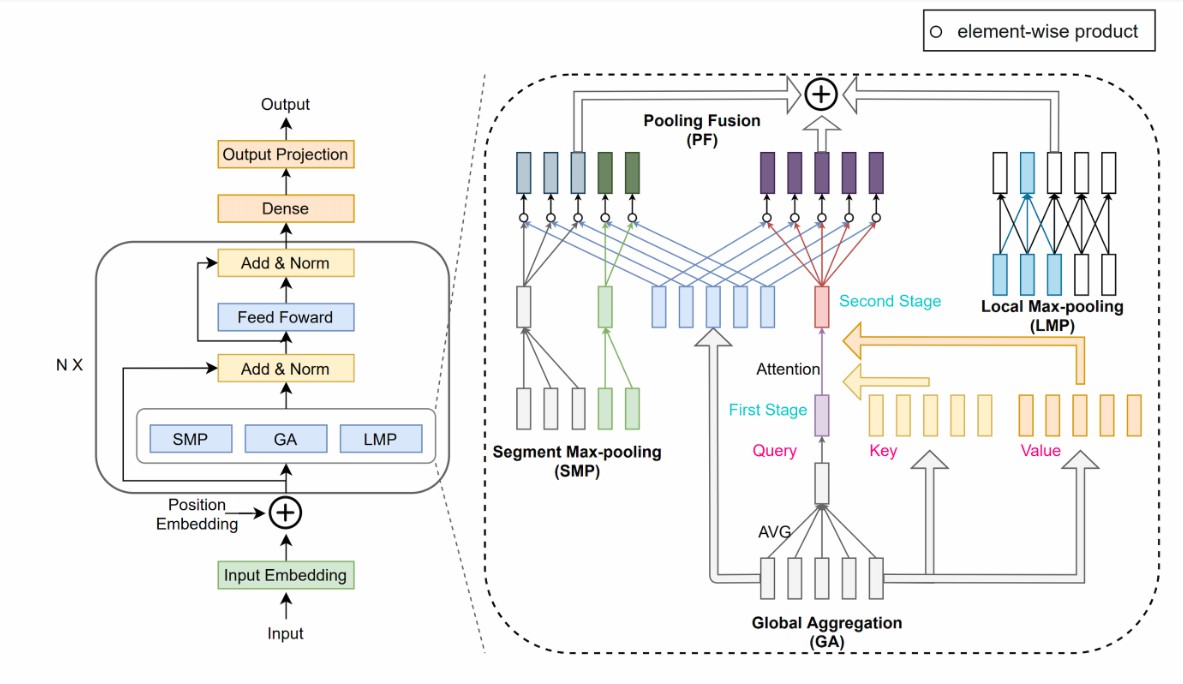
PoNet
実験結果によると、PoNetは長文テキストテストLong Range Arena(LRA)でTransformerよりも2.28ポイント精度が高く、GPUでの実行速度はTransformerの9倍で、GPUメモリ使用量は1/10です。また、実験ではPoNetの移転学習能力も示され、PoNet-BaseはGLUE基準でBERT-Baseの95.7%の精度に達しました。詳細は論文「PoNet: Pooling Network for Efficient Token Mixing in Long Sequences」を参照してください。
モデルの使用方法と適用範囲 このモデルは主に完形填空の結果を生成するために使用されます。ユーザーはさまざまな入力文書を試してみることができます。具体的な呼び出し方法是コード例を参照してください。
使用方法 ModelScope-libをインストール一旦完了したら、nlp_ponet_fill-mask_chinese-baseの機能を使用できます。
コード例
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
pipeline_ins = pipeline(Tasks.fill_mask, model='damo/nlp_ponet_fill-mask_chinese-base')
input = "人民文学出版社[MASK]1952[MASK],出版《[MASK][MASK]演义》、《[MASK]游记》、《水浒传》、《[MASK]楼梦》,合为“[MASK]大名著”。"
print(pipeline_ins(input))モデルの限界と可能性のあるバイアス モデルのトレーニングデータは限定的であり、効果に一定のバイアスが存在する可能性があります。 現在のバージョンはpytorch 1.11とpytorch 1.12環境でテストされていますが、他の環境での動作はテスト待ちです。
トレーニングデータ紹介 データはhttps://dumps.wikimedia.org/ から得られています。
モデルトレーニングプロセス 中国語Wikipediaの非監督データに基づいて、MLMとSSOタスクでトレーニングされました。
前処理 トレーニングデータに対して以下の前処理が行われます。MLMタスクでは、マスク確率を15%に設定し、80%のマスク位置は[MASK]に置き換えられ、10%はランダムにサンプリングされた単語に置き換えられ、残りの10%は変更されません。SSOタスクでは、複数の段落を含むシーケンスがランダムな位置で2つの子シーケンスに截断され、そのうち1/3の確率で別のランダムに選択された子シーケンスに其中一个子序列(其中一个子序列)を置き換え、1/3の確率で二つの子シーケンスを交換、1/3の確率で変更されません。
トレーニング詳細 中国語WikipediaでAdamオプティマイザを使用し、初期学習率为1e-4、batch_sizeは384に設定されています。
データ評価及び結果 下游タスクでfine-tune後、CAIL、CLUEの開発セットの結果は次の通りです。
| データセット Dataset | CAIL | AFQMC | CMNLI | CSL | IFLYTEK | OCNLI | TNEWS | WSC |
|---|---|---|---|---|---|---|---|---|
| 精度 Accuracy | 61.93 | 70.25 | 72.9 | 72.97 | 58.21 | 68.14 | 55.04 | 64.47 |
下游タスクMUGの話題分割(Topic Segmentation)および話題レベルおよびセッションレベルの抽出式要約(Extractive Summarization)の開発セットの結果は次の通りです:
| タスク Task | 正確さ Positive F1 |
|---|---|
| 話題分割 Topic Segmentation | 0.251 |
| タスク Task | 平均R1 Ave. R1 | 平均R2 Ave. R2 | 平均RL Ave. RL | 最大R1 Max R1 | 最大R2 Max R2 | 最大RL Max RL |
|---|---|---|---|---|---|---|
| セッションレベルES Session-Level ES | 57.08 | 29.90 | 38.36 | 62.20 | 37.34 | 46.98 |
| 話題レベルES Topic-Level ES | 52.86 | 35.80 | 46.09 | 66.67 | 54.05 | 63.14 |
詳細はhttps://github.com/alibaba-damo-academy/SpokenNLP で確認できます。
関連論文および引用情報 もし私たちのモデルが役に立ったら、私たちの論文を引用してください。
@inproceedings{DBLP:journals/corr/abs-2110-02442, author = {Chao{-}Hong Tan and Qian Chen and Wen Wang and Qinglin Zhang and Siqi Zheng and Zhen{-}Hua Ling}, title = {{PoNet}: Pooling Network for Efficient Token Mixing in Long Sequences}, booktitle = {10th International Conference on Learning Representations, {ICLR} 2022, Virtual Event, April 25-29, 2022}, publisher = {OpenReview.net}, year = {2022}, url = {https://openreview.net/forum?id=9jInD9JjicF}, }
ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?

