StructBERTの中国語Largeサイズのプリトレーニングモデルは、wikipediaデータとmasked language modelタスクを使用してトレーニングされた中国語自然言語理解プリトレーニングモデルです。
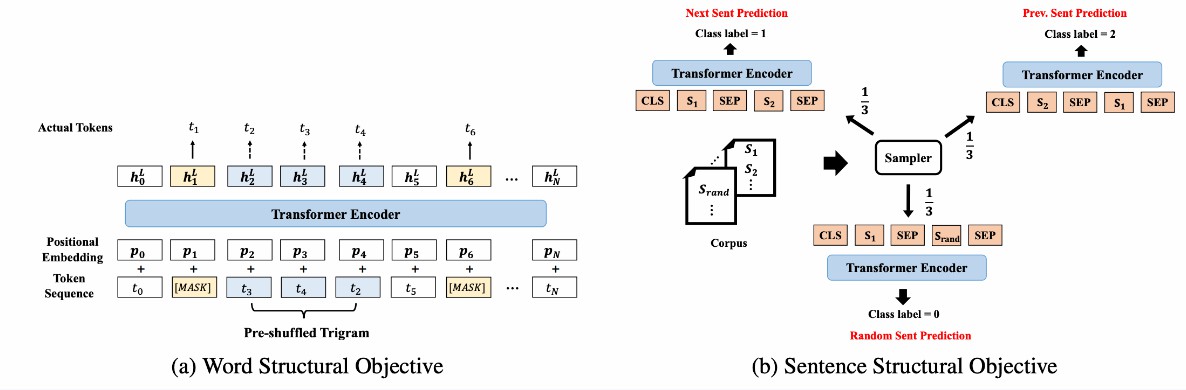
モデル説明 私たちは言語構造情報を導入することで、BERTを新しいモデルStructBERTに拡張しました。モデルが文字レベルの順序情報と文レベルの順序情報を学習するように、2つの補助タスクを導入しました。これにより、言語構造をより良いものとモデル化できます。詳細は論文「StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding StructBERT」を参照してください。
このモデルはTinyサイズ(Layer-4 / Hidden-256 / Head-4)で、パラメーターサイズは約9Mです。
モデルの使用方法と適用範囲 このモデルは主に中国語関連のダウンストリームタスクのファインチューニングに使用されます。ユーザーは独自のトレーニングデータを使用してファインチューニングを実行できます。具体的な呼び出し方法はコードサンプルを参照してください。
使用方法 ModelScope-libをインストール後、nlp_structbert_backbone_tiny_stdを使用してダウンストリームタスクのfine-tuneを実行できます。
コードサンプル
from modelscope.metainfo import Preprocessors
from modelscope.msdatasets import MsDataset
from modelscope.trainers import build_trainer
from modelscope.utils.constant import Tasks
# このメソッドを通じてcfgを変更
def cfg_modify_fn(cfg):
# バックボーンモデルを文の類似度モデルクラスにロード
cfg.task = Tasks.sentence_similarity
# 文の類似度のプリプロセッサを使用
cfg['preprocessor'] = {'type': Preprocessors.sen_sim_tokenizer}
# デモコードの変更、通常は変更不要
cfg.train.dataloader.workers_per_gpu = 0
cfg.evaluation.dataloader.workers_per_gpu = 0
# データセットの特徴を補足
cfg['dataset'] = {
'train': {
# 実際のlabelフィールド内容の列挙、バックボーンのトレーニング時に入力必要
'labels': ['0', '1'],
# 最初のフィールドのkey
'first_sequence': 'sentence1',
# 2番目のフィールドのkey
'second_sequence': 'sentence2',
# labelのkey
'label': 'label',
}
}
# lr_schedulerの設定
cfg.train.lr_scheduler.total_iters = int(len(dataset['train']) / 32) * cfg.train.max_epochs
return cfg
# clueのafqmcを使用してトレーニング
dataset = MsDataset.load('clue', subset_name='afqmc')
kwargs = dict(
model='damo/nlp_structbert_backbone_tiny_std',
train_dataset=dataset['train'],
eval_dataset=dataset['validation'],
work_dir='/tmp',
cfg_modify_fn=cfg_modify_fn)
# nlp-base-trainerを使用
trainer = build_trainer(name='nlp-base-trainer', default_args=kwargs)
trainer.train()モデルの限界と可能性のあるバイアス 中国語データに基づいてトレーニングされ、モデルのトレーニングデータが限られているため、効果に一定のバイアスが存在する可能性があります。
トレーニングデータ紹介 データはhttps://huggingface.co/datasets/wikipedia から来ています。現在、ネットワークの原因により、このウェブページの解析に成功しませんでした。もし必要であれば、ウェブページリンクの合法性をチェックし、適宜リトライしてください。
モデルトレーニングプロセス 中国語wikiなどの無監督データで、MLMおよび「モデル説明」の章で紹介された2つの補助タスクを通じて約300B字をトレーニングしました。
データ評価及び結果 まだありません
関連論文および引用情報 もし私たちのモデルが役立ちましたら、以下の論文を引用してください:
@article{wang2019structbert, title={Structbert: Incorporating language structures into pre-training for deep language understanding}, author={Wang, Wei and Bi, Bin and Yan, Ming and Wu, Chen and Bao, Zuyi and Xia, Jiangnan and Peng, Liwei and Si, Luo}, journal={arXiv preprint arXiv:1908.04577}, year={2019} } ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?

