このモデルはStructBERTプリトレーニングモデルをベースに、400GBの司法語料を使用してプリトレーニングされています。トレーニング語料には、判決文書、法律法規、裁判記録、法律Q&A、法律百科など、司法分野のテキストが含まれています。

モデル説明 CAIL2022競技大会チャンピオンシリーズモデルベース
このモデルはBaseサイズ(Layer-12 / Hidden-768 / Head-12)で、パラメーターサイズは約102Mです。
tinyバージョンモデル:StructBERTプリトレーニングモデル-中国語-法律分野-tiny
liteバージョンモデル:StructBERTプリトレーニングモデル-中国語-法律分野-lite
文書校正モデル:BARTテキスト訂正-中国語-法律分野-large
さらに多くのモデルがオープンソースとしてリリースされる予定です。ご期待ください。
プリトレーニング語料 200GBの一般語料と400GBの司法語料を合わせて2150億のトークンをカバーし、判決文書、法律法規、裁判記録、法律Q&A、法律百科など、司法分野のテキストが含まれています。司法文書のフォーマットは非常に規則的であるため、モデルの過剰適合を防ぐために、独自の司法文書構造化エンジンを使用して、司法文書の各種段落(訴訟情況、弁護意見、事実認定、審理経過など)を識別し、異なる司法テキスト内容に対して異なるサンプリングルールを適用しました。
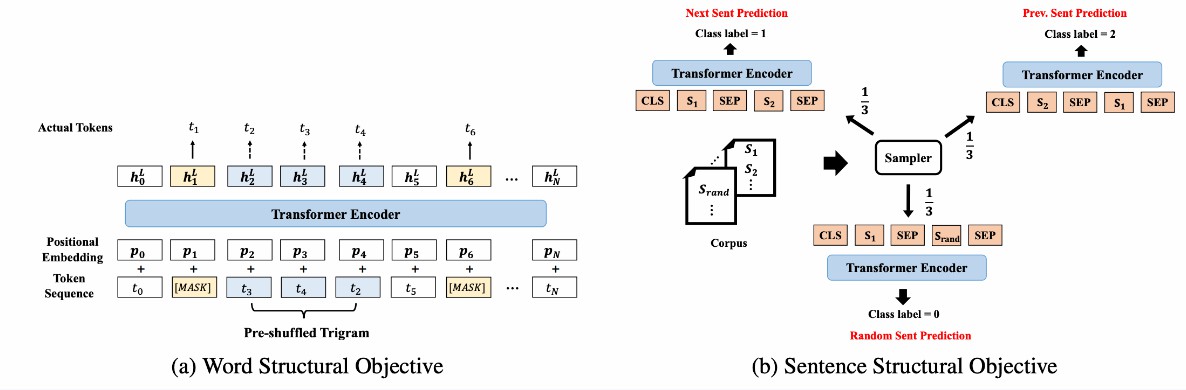
プリトレーニングタスク プリトレーニングタスクでは、トークンレベルと文レベルのタスクを組み合わせています。トークンレベルのプリトレーニングタスクは主にMLMタスクを中心とし、シャッフルタスクとランダムタスクの予測を補助します。文レベルのプリトレーニングタスクは主にSimCSEを中心としています。
モデルの使用方法と適用範囲 このモデルは主に中国語関連のダウンストリームタスクのファインチューニングに使用されます。ユーザーは独自のトレーニングデータを使用してファインチューニングを実行できます。具体的な呼び出し方法はコードサンプルを参照してください。
使用方法 ModelScopeをインストール後、nlp_structbert_backbone_base_lawを使用してダウンストリームタスクのfine-tuneを実行できます。
コードサンプル
from modelscope.metainfo import Preprocessors
from modelscope.msdatasets import MsDataset
from modelscope.trainers import build_trainer
from modelscope.utils.constant import Tasks
# このメソッドを通じてcfgを変更
def cfg_modify_fn(cfg):
# バックボーンモデルを文の類似度モデルクラスにロード
cfg.task = Tasks.sentence_similarity
# 文の類似度のプリプロセッサを使用
cfg['preprocessor'] = {'type': Preprocessors.sen_sim_tokenizer}
# デモコードの変更、通常は変更不要
cfg.train.dataloader.workers_per_gpu = 0
cfg.evaluation.dataloader.workers_per_gpu = 0
# データセットの特徴を補足
cfg['dataset'] = {
'train': {
# 実際のlabelフィールド内容の列挙、バックボーンのトレーニング時に入力必要
'labels': ['0', '1'],
# 最初のフィールドのkey
'first_sequence': 'sentence1',
# 2番目のフィールドのkey
'second_sequence': 'sentence2',
# labelのkey
'label': 'label',
}
}
# lr_schedulerの設定
cfg.train.lr_scheduler.total_iters = int(len(dataset['train']) / 32) * cfg.train.max_epochs
return cfg
# clueのafqmcを使用してトレーニング
dataset = MsDataset.load('clue', subset_name='afqmc')
kwargs = dict(
model='damo/nlp_structbert_backbone_base_law',
train_dataset=dataset['train'],
eval_dataset=dataset['validation'],
work_dir='/tmp',
cfg_modify_fn=cfg_modify_fn)
# nlp-base-trainerを使用
trainer = build_trainer(name='nlp-base-trainer', default_args=kwargs)
trainer.train()モデルの限界と可能性のあるバイアス 司法分野のデータに基づいてトレーニングされ、他の分野での性能には一定のバイアスが存在する可能性があります。
モデル評価及び結果
司法プリトレーニングモデルの評価及び結果
【注:为了更公平な比較、スコアの変動を減らすために、各モデルは5回のランダムイニシャルIZATIONを経て、最終的に5回のスコアの平均を成績として使用します。】
| モデル | スコア | パラメータ量 | 危険運転起訴书 | 危険運転記録 | 判決书・訴訟 | 判決书・事実認定 | 判決书・本院认为 |
|---|---|---|---|---|---|---|---|
| sbert-tiny-std | 68.522 | 9 M | 90.55 | 59.27 | 68.78 | 74.30 | 49.71 |
| sbert-tiny-legal | 69.234 | 9 M | 91.48 | 59.63 | 69.38 | 75.53 | 50.15 |
| sbert-lite-std | 70.838 | 30 M | 93.08 | 64.09 | 70.16 | 74.68 | 52.18 |
| sbert-lite-legal | 71.002 | 30 M | 93.42 | 64.33 | 70.26 | 75.37 | 51.63 |
| sbert-base-std | 72.274 | 102 M | 94.67 | 67.69 | 70.99 | 75.57 | 52.45 |
| sbert-base-legal | 72.344 | 102 M | 94.71 | 66.90 | 71.27 | 75.59 | 53.25 |
【注:以下はfew-shotのランキングで、训练データの5%のみを使用しています。】
| モデル | スコア | パラメータ量 | 危険運転起訴书 | 危険運転記録 | 判決书・訴訟 | 判決书・事実認定 | 判決书・本院认为 |
|---|---|---|---|---|---|---|---|
| sbert-tiny-std | 51.722 | 9 M | 83.81 | 47.02 | 51.38 | 53.51 | 22.89 |
| sbert-tiny-legal | 53.774 | 9 M | 83.13 | 47.55 | 56.01 | 57.08 | 25.10 |
| sbert-lite-std | 62.134 | 30 M | 89.67 | 55.71 | 61.30 | 67.77 | 36.22 |
| sbert-lite-legal | 63.452 | 30 M | 89.89 | 56.97 | 63.09 | 69.48 | 37.83 |
| sbert-base-std | 66.056 | 102 M | 90.79 | 62.33 | 64.70 | 71.30 | 41.16 |
| sbert-base-legal | 66.232 | 102 M | 91.37 | 61.81 | 65.36 | 71.22 | 41.40 |
関連論文および引用情報 @article{wang2019structbert, title={Structbert: Incorporating language structures into pre-training for deep language understanding}, author={Wang, Wei and Bi, Bin and Yan, Ming and Wu, Chen and Bao, Zuyi and Xia, Jiangnan and Peng, Liwei and Si, Luo}, journal={arXiv preprint arXiv:1908.04577}, year={2019} } ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?