概要
TÜLU 3は、Allen Institute for Artificial Intelligenceとワシントン大学の研究チームによって提供されるオープンソースの後トレーニングモデルシリーズです。チャット機能だけでなく、数学(MATH)、GSM8K、IFEvalなどさまざまなタスクで最先端の性能を実現しています。TÜLU 3は8Bと70Bの2つのバージョンを提供しており、その包括的な後トレーニングスキームは、トピックの選択からデータガバナンス、強化学習から微調整までの全方位プロセスをカバーしています。ユーザーは、数学やプログラミングの能力を強化するなど、モデルの能力を必要に応じて調整することができます。
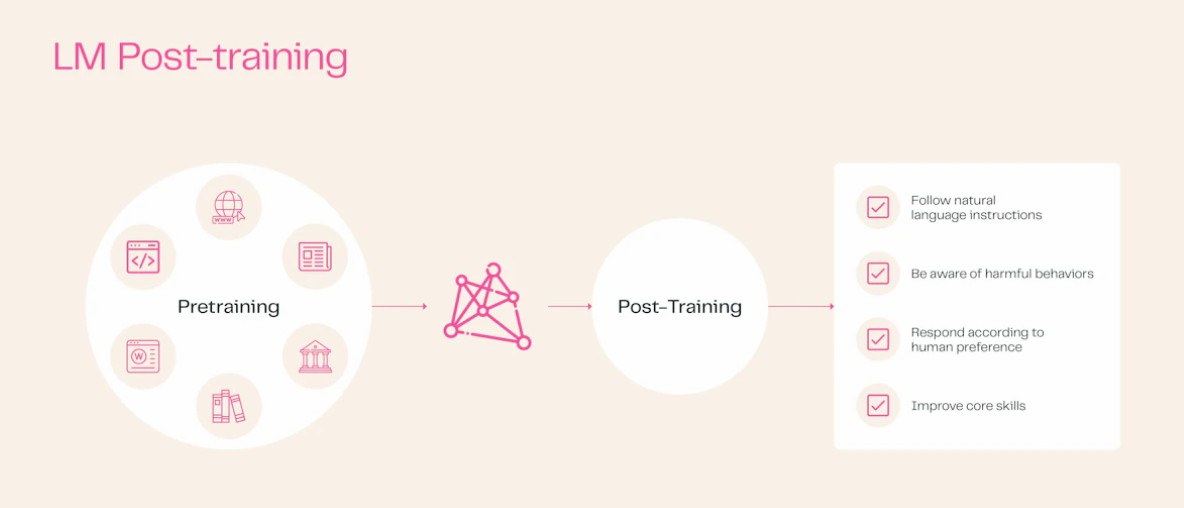
後トレーニングの重要性
一般的な認識とは異なり、基本的な言語モデルはプリトレーニング後すぐに使用できるわけではありません。後トレーニングプロセスがモデルの最終的な価値を決定する鍵です。この段階で、モデルは「何でも知っている」が判断力に欠けるネットワークから、特定の機能指向の実用ツールに変わります。
TÜLU 3の後トレーニングスキーム
TÜLU 3の後トレーニングスキームには、次の4つの主要なステップがあります:
1.多様で高品質なプロンプトの構築:多様なトピックと高品質なデータを選択し、モデルに豊富なトレーニング素材を提供します。
2.監視された微調整(SFT):慎重に選択されたデータセットを使用してモデルを微調整し、数学やプログラミングなどの特定のスキルにおけるモデルの性能を強化します。
3.偏好最適化(DPO):偏好フィードバックに基づく最適化手法で、追加の報酬モデルを必要とせずに、直接偏好データから学習し、モデルがユーザーの偏好に更好地適応できるようにします。
4.強化学習(RLVR):数学問題の解決などの検証可能なタスクでは、モデルの出力が正しい場合にのみ報酬を与えることで、タスクにおけるモデルの性能を向上させます。
パフォーマンス
TÜLU 3はLlama 3.1の基本モデルに基づいており、その結果はLlama 3.1、Qwen 2.5、Mistralのinstructバージョンを超え、GPT-4o-miniやClaude 3.5-Haikuなどのクローズドソースモデルさえも上回っています。TÜLU 3のトレーニングアルゴリズムには、監視された微調整(SFT)、直接偏好最適化(DPO)、検証可能な報酬の強化学習(RLVR)が含まれており、これらの技術の適用によりモデルのパフォーマンスが大幅に向上しています。
リソースリンク
-
論文アドレス:TÜLU 3 論文
-
モデルダウンロード:TÜLU 3 モデル
-
コードアドレス:TÜLU 3 コード
-
Demoアドレス:TÜLU 3 オンライン体験
結語
TÜLU 3のリリースは、オープンソースモデルの発展に新しい基準を設け、その包括的な後トレーニング技術レポートと公開されたデータ、評価コード、トレーニングアルゴリズムは、研究者と開発者にとって貴重なリソースを提供しています。TÜLU 3は、既存のオープンソースモデルを上回る性能だけでなく、複数の分野でその強力なアプリケーションポテンシャルを示しています。
aiスピーキング
ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?