モデル紹介
Megrez-3B-Omniは、無問芯穹(Infinigence AI)によって開発されたエッジ側の全モーダル理解モデルで、無問の大言語モデルMegrez-3B-Instructを拡張し、画像、テキスト、音声の3つのモーダルデータを理解・分析する能力を持ち、各分野で最優精度を達成しています。
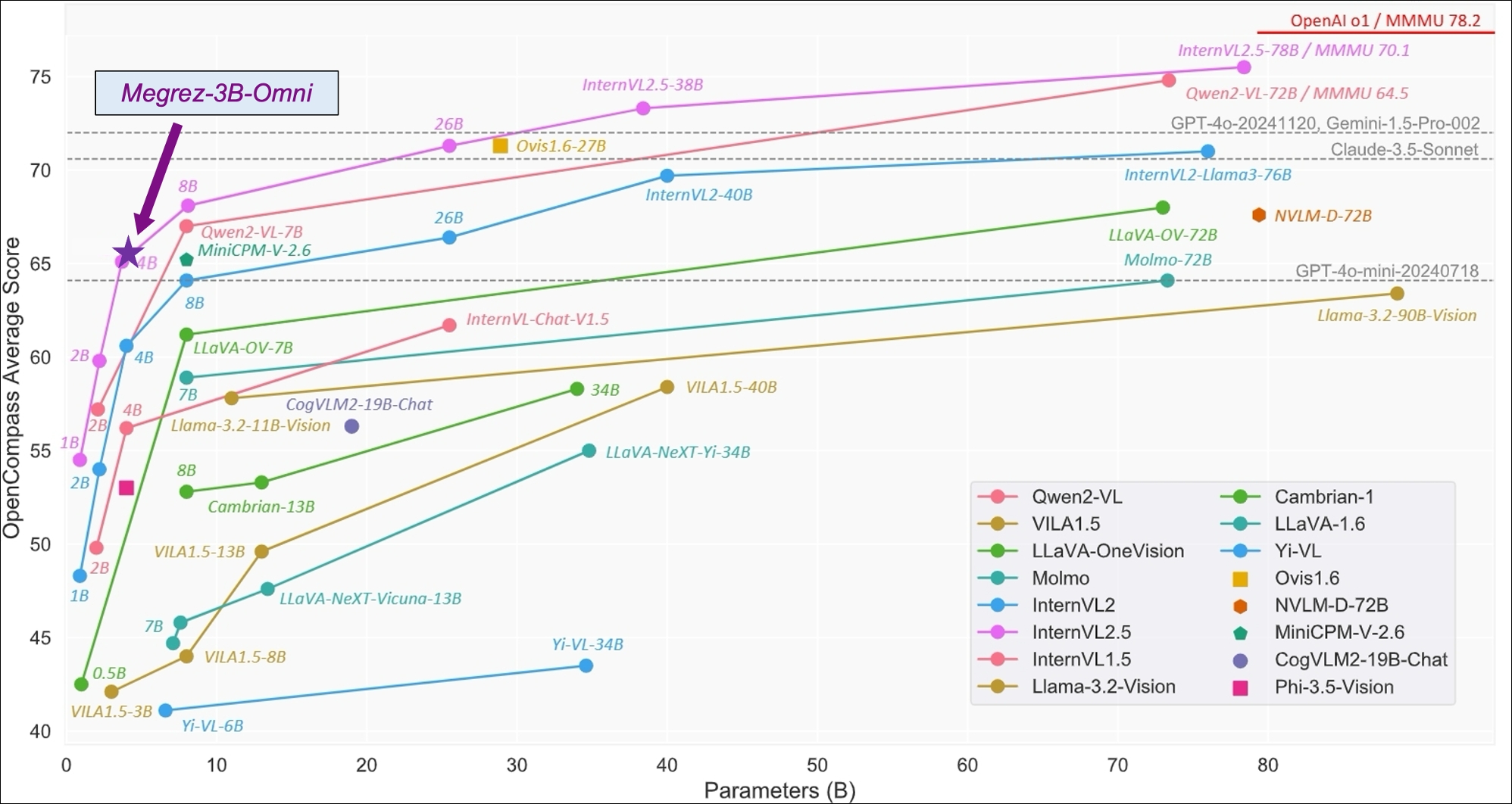
画像理解においては、SigLip-400Mをベースに画像Tokenを構築し、OpenCompassランキング(8つの主要なマルチモーダル評価基準を総合)で平均66.2点とし、LLaVA-NeXT-Yi-34Bなどのよりパラメーターが多いモデルを凌駕します。Megrez-3B-Omniはまた、MME、MMMU、OCRBenchなどのテストセットで現在最高精度の画像理解モデルの一つであり、シーン理解、OCRなどで良好なパフォーマンスを示しています。 言語理解においては、Megrez-3B-Omniはモデルのテキスト処理能力を犠牲にせず、シングルモーダルバージョン(Megrez-3B-Instruct)に比べて総合精度が2%以内に抑えられており、C-EVAL、MMLU/MMLU Pro、AlignBenchなどの複数のテストセットで最優精度を維持し、前世代の14Bモデルを超える能力を発揮しています。 音声理解においては、Qwen2-Audio/whisper-large-v3のEncoderを音声入力として使用し、中国語と英語の音声入力と複数ラウンド対話をサポートし、入力画像に対する音声質問に対応し、音声コマンドに基づいて直接テキストをレスポンスするなど、数多くの基準タスクで领先した結果を達成しています。
基本情報
| Language Module | Vision Module | Audio Module | |
|---|---|---|---|
| Architecture | Llama-2 with GQA | SigLip-SO400M | Whisper-large-v3 (encoder-only) |
| # Params (Backbone) | 2.29B | 0.42B | 0.64B |
| Connector | - | Cross Attention | Linear |
| # Params (Others) | Emb: 0.31B Softmax: 0.31B |
Connector: 0.036B | Connector: 0.003B |
| # Params (Total) | 4B | ||
| # Vocab Size | 122880 | 64 tokens/slice | - |
| Context length | 4K tokens | ||
| Supported languages | Chinese & English |
画像理解能力
上図はMegrez-3B-Omniと他のオープンソースモデルが主流の画像マルチモーダルタスクにおける性能比較です。
下図はMegrez-3B-OmniがOpenCompassテストセットでの実績で、画像はInternVL 2.5 Blog Postから引用します。
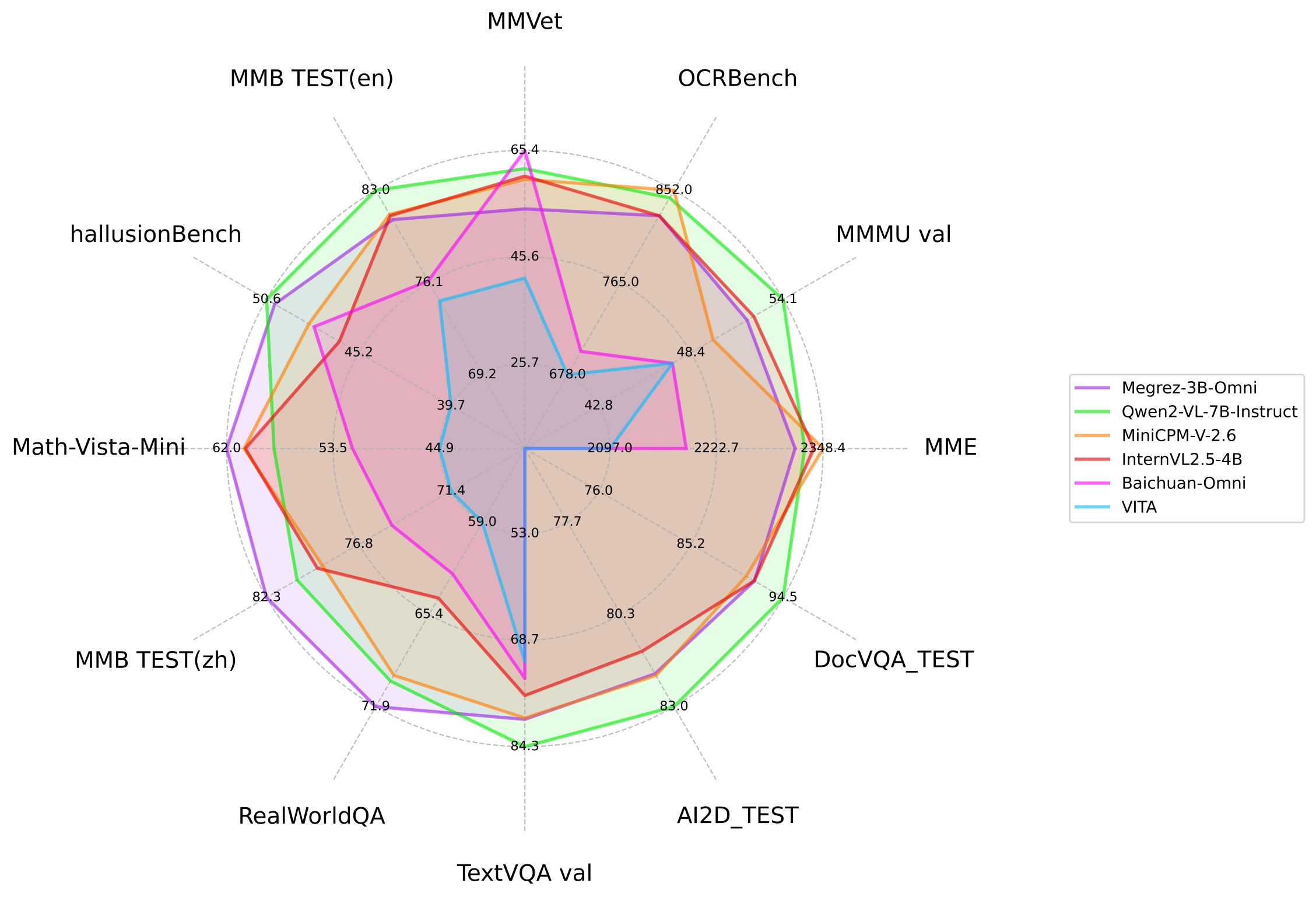
| モデル | ベースモデル | 発表時間 | OpenCompass | MME | MMMU val | OCRBench | MathVista | RealWorldQA | MMVet | hallucinationBench | MMB TEST (en) | MMB TEST (zh) | TextVQA val | AI2D_TEST | MMstar | DocVQA_TEST |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Megrez-3B-Omni | Megrez-3B | 2024.12.16 | 66.2 | 2315 | 51.89 | 82.8 | 62 | 71.89 | 60 | 50.12 | 80.8 | 82.3 | 80.3 | 82.05 | 60.46 | 91.62 |
| Qwen2-VL-2B-Instruct | Qwen2-1.5B | 2024.08.28 | 57.2 | 1872 | 41.1 | 79.4 | 43 | 62.9 | 49.5 | 41.7 | 74.9 | 73.5 | 79.7 | 74.7 | 48 | 90.1 |
| InternVL2.5-2B | Internlm2.5-1.8B-chat | 2024.12.06 | 59.9 | 2138 | 43.6 | 80.4 | 51.3 | 60.1 | 60.8 | 42.6 | 74.7 | 71.9 | 74.3 | 74.9 | 53.7 | 88.7 |
| BlueLM-V-3B | - | 2024.11.29 | 66.1 | - | 45.1 | 82.9 | 60.8 | 66.7 | 61.8 | 48 | 83 | 80.5 | 78.4 | 85.3 | 62.3 | 87.8 |
| InternVL2.5-4B | Qwen2.5-3B-Instruct | 2024.12.06 | 65.1 | 2337 | 52.3 | 82.8 | 60.5 | 64.3 | 60.6 | 46.3 | 81.1 | 79.3 | 76.8 | 81.4 | 58.3 | 91.6 |
| Baichuan-Omni | Unknown-7B | 2024.10.11 | - | 2186 | 47.3 | 70.0 | 51.9 | 62.6 | 65.4 | 47.8 | 76.2 | 74.9 | 74.3 | - | - | - |
| MiniCPM-V-2.6 | Qwen2-7B | 2024.08.06 | 65.2 | 2348 | 49.8 | 85.2 | 60.6 | 69.7 | 60 | 48.1 | 81.2 | 79 | 80.1 | 82.1 | 57.26 | 90.8 |
| Qwen2-VL-7B-Instruct | Qwen2-7B | 2024.08.28 | 67 | 2326 | 54.1 | 84.5 | 58.2 | 70.1 | 62 | 50.6 | 83 | 80.5 | 84.3 | 83 | 60.7 | 94.5 |
| MiniCPM-Llama3-V-2.5 | Llama3-Instruct 8B | 2024.05.20 | 58.8 | 2024 | 45.8 | 72.5 | 54.3 | 63.5 | 52.8 | 42.4 | 77.2 | 74.2 | 76.6 | 78.4 | - | 84.8 |
| VITA | Mixtral 8x7B | 2024.08.12 | - | 2097 | 47.3 | 67.8 | 44.9 | 59 | 41.6 | 39.7 | 74.7 | 71.4 | 71.8 | - | - | - |
| GLM-4V-9B | GLM-4-9B | 2024.06.04 | 59.1 | 2018 | 46.9 | 77.6 | 51.1 | - | 58 | 46.6 | 81.1 | 79.4 | - | 81.1 | 58.7 | - |
| LLaVA-NeXT-Yi-34B | Yi-34B | 2024.01.18 | 55 | 2006 | 48.8 | 57.4 | 40.4 | 66 | 50.7 | 34.8 | 81.1 | 79 | 69.3 | 78.9 | 51.6 | - |
| Qwen2-VL-72B-Instruct | Qwen2-72B | 2024.08.28 | 74.8 | 2482 | 64.5 | 87.7 | 70.5 | 77.8 | 74 | 58.1 | 86.5 | 86.6 | 85.5 | 88.1 | 68.3 | 96.5 |
文書処理能力
| 対話&指令 | 中国語&英語タスク | コードタスク | 数学タスク | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| モデル | ダイアログ&コマンド | 発表時間 | # Non-Emb Params | MT-Bench | AlignBench (ZH) | IFEval | C-EVAL (ZH) | CMMLU (ZH) | MMLU | MMLU-Pro | HumanEval | MBPP | GSM8K | MATH |
| Megrez-3B-Omni | はい | 2024.12.16 | 2.3 | 8.4 | 6.94 | 66.5 | 84.0 | 75.3 | 73.3 | 45.2 | 72.6 | 60.6 | 63.8 | 27.3 |
| Megrez-3B-Instruct | はい | 2024.12.16 | 2.3 | 8.64 | 7.06 | 68.6 | 84.8 | 74.7 | 72.8 | 46.1 | 78.7 | 71.0 | 65.5 | 28.3 |
| Baichuan-Omni | はい | 2024.10.11 | 7.0 | - | - | - | 68.9 | 72.2 | 65.3 | - | - | - | - | - |
| VITA | はい | 2024.08.12 | 12.9 | - | - | - | 56.7 | 46.6 | 71.0 | - | - | 75.7 | - | - |
| Qwen1.5-7B | いいえ | 2024.02.04 | 6.5 | - | - | - | 74.1 | 73.1 | 61.0 | 29.9 | 36.0 | 51.6 | 62.5 | 20.3 |
| Qwen1.5-7B-Chat | はい | 2024.02.04 | 6.5 | 7.60 | 6.20 | - | 67.3 | - | 59.5 | 29.1 | 46.3 | 48.9 | 60.3 | 23.2 |
| Qwen1.5-14B | いいえ | 2024.02.04 | 12.6 | - | - | - | 78.7 | 77.6 | 67.6 | - | 37.8 | 44.0 | 70.1 | 29.2 |
| Qwen1.5-14B-Chat | はい | 2024.02.04 | 12.6 | 7.9 | - | - | - | - | - | - | - | - | - | - |
| Qwen2-7B | いいえ | 2024.06.07 | 6.5 | - | - | - | 83.2 | 83.9 | 70.3 | 40.0 | 51.2 | 65.9 | 79.9 | 44.2 |
| Qwen2-7b-Instruct | はい | 2024.06.07 | 6.5 | 8.41 | 7.21 | 51.4 | 80.9 | 77.2 | 70.5 | 44.1 | 79.9 | 67.2 | 85.7 | 52.9 |
| Qwen2.5-3B-Instruct | はい | 2024.9.19 | 2.8 | - | - | - | - | - | - | 43.7 | 74.4 | 72.7 | 86.7 | 65.9 |
| Qwen2.5-7B | いいえ | 2024.9.19 | 6.5 | - | - | - | - | - | 74.2 | 45.0 | 57.9 | 74.9 | 85.4 | 49.8 |
| Qwen2.5-7B-Instruct | はい | 2024.09.19 | 6.5 | 8.75 | - | 74.9 | - | - | - | 56.3 | 84.8 | 79.2 | 91.6 | 75.5 |
| Llama-3.1-8B | いいえ | 2024.07.23 | 7.0 | 8.3 | 5.7 | 71.5 | 55.2 | 55.8 | 66.7 | 37.1 | - | - | 84.5 | 51.9 |
| Llama-3.2-3B | いいえ | 2024.09.25 | 2.8 | - | - | 77.4 | - | - | 63.4 | - | - | - | 77.7 | 48.0 |
| Phi-3.5-mini-instruct | はい | 2024.08.23 | 3.6 | 8.6 | 5.7 | 49.4 | 46.1 | 46.9 | 69.0 | 47.4 | 62.8 | 69.6 | 86.2 | 48.5 |
| MiniCPM3-4B | はい | 2024.09.05 | 3.9 | 8.41 | 6.74 | 68.4 | 73.6 | 73.3 | 67.2 | - | 74.4 | 72.5 | 81.1 | 46.6 |
| Yi-1.5-6B-Chat | はい | 2024.05.11 | 5.5 | 7.50 | 6.20 | - | 74.2 | 74.7 | 61.0 | - | 64.0 | 70.9 | 78.9 | 40.5 |
| GLM-4-9B-chat | はい | 2024.06.04 | 8.2 | 8.35 | 7.01 | 64.5 | 75.6 | 71.5 | 72.4 | - | 71.8 | - | 79.6 | 50.6 |
| Baichuan2-13B-Base | いいえ | 2023.09.06 | 12.6 | - | 5.25 | - | 58.1 | 62.0 | 59.2 | - | 17.1 | 30.2 | 52.8 | 10.1 |
注:Qwen2-1.5Bモデルの指標が論文とQwen2.5報告で点数が不一致の場合がありますが、今回は原論文の精度を採用しています。
音声理解能力
| モデル | ベースモデル | リリース時間 | Fleurs テスト-中国語 | WenetSpeech テスト_ネット | WenetSpeech テスト_会議 |
|---|---|---|---|---|---|
| Megrez-3B-Omni | Megrez-3B-Instruct | 2024.12.16 | 10.8 | - | 16.4 |
| Whisper-large-v3 | - | 2023.11.06 | 12.4 | 17.5 | 30.8 |
| Qwen2-Audio-7B | Qwen2-7B | 2024.08.09 | 9 | 11 | 10.7 |
| Baichuan2-omni | Unknown-7B | 2024.10.11 | 7 | 6.9 | 8.4 |
| VITA | Mixtral 8x7B | 2024.08.12 | - | -/12.2(CER) | -/16.5(CER) |
速度
| image_tokens | prefill (tokens/s) | decode (tokens/s) | |
|---|---|---|---|
| Megrez-3B-Omni | 448 | 6312.66 | 1294.9 |
| Qwen2-VL-2B | 1378 | 7349.39 | 685.66 |
| MiniCPM-V-2_6 | 448 | 2167.09 | 452.51 |
请注意,表格中的"-"表示没有提供数据或者不适用。"CER"是Character Error Rate(文字誤り率)的缩写,用于衡量语音识别系统的准确性。
実験設定:
テスト環境:NVIDIA H100、vLLM下で128個のText tokenと1480x720サイズの画像を入力し、128個のtokenを出力し、num_seqsを固定して8
快速開始
オンライン体験 HF Chat Demo
ローカルデプロイ 環境インストールとvLLM推論コードなどのデプロイ問題については、Infini-Megrez-Omniを参照してください。
以下はtransformersを使用して推論を行う例です。contentフィールドにtext、image、audioを渡すことで、図文/図音などの多種多様なモーダルとモデルと対話できます。
import torch
from transformers import AutoModelForCausalLM
path = "{{PATH_TO_PRETRAINED_MODEL}}" # Change this to the path of the model.
model = (
AutoModelForCausalLM.from_pretrained(
path,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
.eval()
.cuda()
)
# テキストと画像でチャット
messages = [
{
"role": "user",
"content": {
"text": "Please describe the content of the image.",
"image": "./data/sample_image.jpg",
},
},
]
# 音声と画像でチャット
messages = [
{
"role": "user",
"content": {
"image": "./data/sample_image.jpg",
"audio": "./data/sample_audio.m4a",
},
},
]
MAX_NEW_TOKENS = 100
response = model.chat(
messages,
sampling=False,
max_new_tokens=MAX_NEW_TOKENS,
temperature=0,
)
print(response)注意事項: 画像はできるだけ初回入力で読み取ることをお勧めします。音声とテキストはこの制限にとらわれず、自由に切り替え可能です。 音声認識(ASR)シナリオでは、content['text']を「音声を文字に変換してください。」と変更します。 OCRシナリオでは、サンプリングを有効にすると言語モデルの幻觉が原因で文字が変化する可能性があるため、推論 を行う際にはサンプリングをオフすることを検討してください(sampling=False),しかし、サンプリングをオフするとモデルの反復が引き起こされる可能性があります。
オープンソース契約および使用声明: 契約:本レポジトリのコードはApache-2.0契約に基づいてオープンソースです。 幻觉:大きなモデルは自然に幻觉の問題を持ち、ユーザーはモデル生成の内容を完全に信用しないでください。 価値観および安全性:本モデルはトレーニング過程で使用されるデータの規制に従い、全力を尽くしましたが、データの大量及び複雑さのために予期せぬ問題が生じる可能性があります。もしもオープンソースモデルの使用によって生じたいかなる問題も、データセキュリティ問題、公衆の世論リスク、またはモデルが誤解、滥用、伝播、不当な使用に遭ったリスクや問題によって生じた責任や義務については、一切の責任を負いかねます。
aiスピーキング
ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?

