はじめに
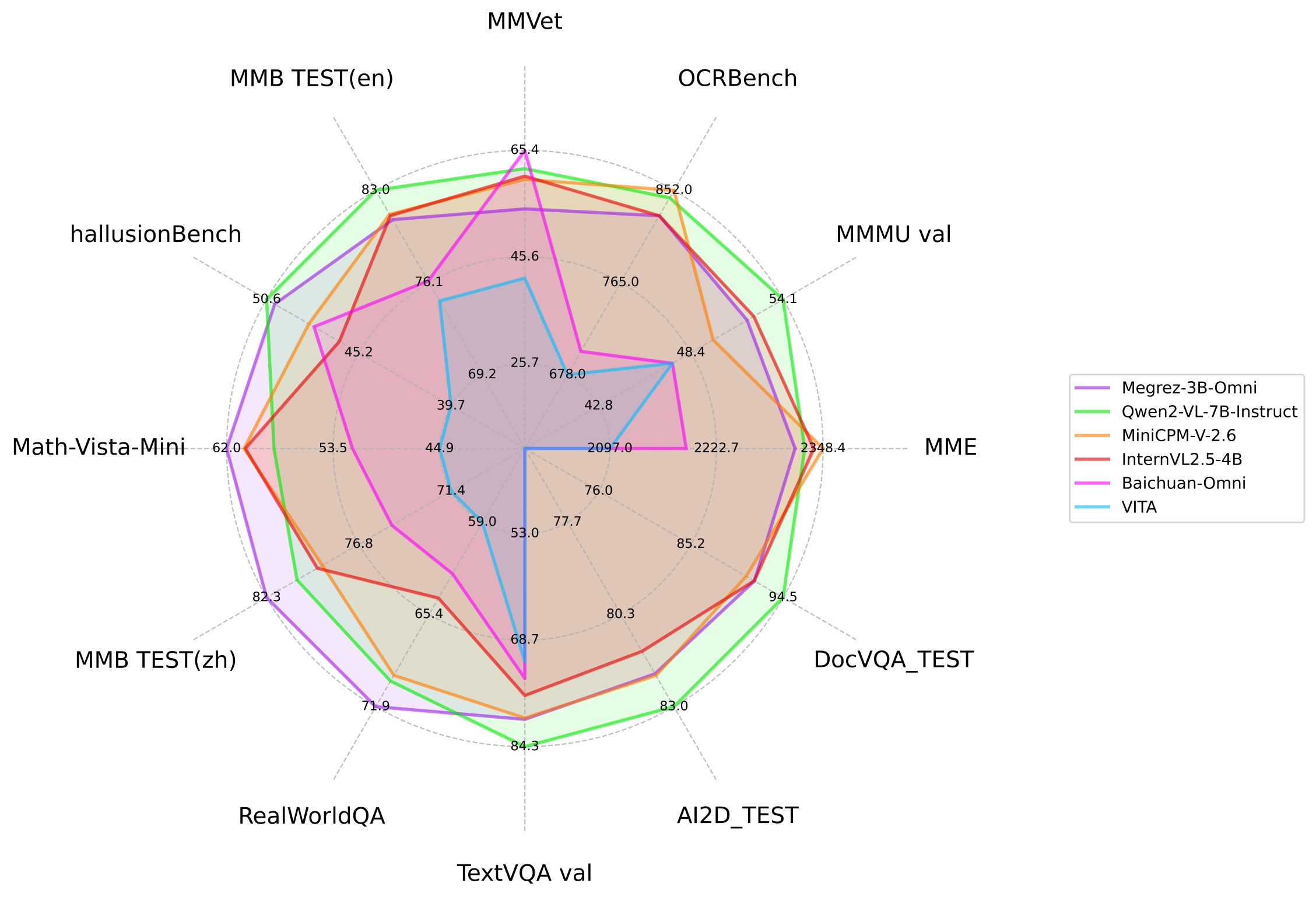
DeepSeek-VL2を紹介します。これは、その前身であるDeepSeek-VLを大きく改良した、高度なシリーズの大きなエキスパート混合型(MoE)ビジョン・ランゲージモデルです。DeepSeek-VL2は、ビジュアルクイズ応答、光学文字認識、文書/テーブル/チャート理解、ビジュアルグラウンドイングなど、多岐にわたるタスクにおいて優れた性能を示しています。私たちのモデルシリーズは、DeepSeek-VL2-Tiny、DeepSeek-VL2-Small、DeepSeek-VL2の3つのバリエーションから成り立ち、それぞれ1.0B、2.8B、4.5Bのアクティブパラメータを持っています。DeepSeek-VL2は、既存のオープンソースの密な型およびMoEベースのモデルに比べて、同様または少ないアクティブパラメータで競争力のあるまたは最先端の性能を達成します。
DeepSeek-VL2:高度なマルチモーダル理解のためのエキスパート混合型ビジョン・ランゲージモデル
Github Repository
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, Zhenda Xie, Yu Wu, Kai Hu, Jiawei Wang, Yaofeng Sun, Yukun Li, Yishi Piao, Kang Guan, Aixin Liu, Xin Xie, Yuxiang You, Kai Dong, Xingkai Yu, Haowei Zhang, Liang Zhao, Yisong Wang, Chong Ruan** ( 同等貢献、 プロジェクトリード、*** 連絡担当著者)

モデル概要
DeepSeek-VL2はDeepSeekMoE-27Bを基盤としています。
クイックスタート
インストール Python >= 3.8環境に基づいて、以下のコマンドを実行して必要な依存関係をインストールします。
pip install -e . シンプルな推論例 import torch from modelscope import AutoModelForCausalLM
from deepseek_vl.models import DeepseekVLV2Processor, DeepseekVLV2ForCausalLM from deepseek_vl.utils.io import load_pil_images
モデルのパスを指定 model_path = "deepseek-ai/deepseek-vl2-small" vl_chat_processor: DeepseekVLV2Processor = DeepseekVLV2Processor.from_pretrained(model_path) tokenizer = vl_chat_processor.tokenizer
vl_gpt: DeepseekVLV2ForCausalLM = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True) vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
シングルイメージ会話例
conversation = [
{
"role": "<|User|>",
"content": "
マルチイメージ(またはインコンテキスト学習)会話例
conversation = [
{
"role": "User",
"content": "
画像を読み込み、入力を準備 pil_images = load_pil_images(conversation) prepare_inputs = vl_chat_processor( conversations=conversation, images=pil_images, force_batchify=True, system_prompt="" ).to(vl_gpt.device)
画像エンコーダーを実行して画像の埋め込みを得る inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
モデルを実行して応答を得る outputs = vl_gpt.language_model.generate( inputs_embeds=inputs_embeds, attention_mask=prepare_inputs.attention_mask, pad_token_id=tokenizer.eos_token_id, bos_token_id=tokenizer.bos_token_id, eos_token_id=tokenizer.eos_token_id, max_new_tokens=512, do_sample=False, use_cache=True )
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True) print(f"{prepare_inputs['sft_format'][0]}", answer) Gradioデモ(TODO)
ライセンス
このコードレポジトリはMITライセンスに基づいており、DeepSeek-VL2モデルの使用はDeepSeekモデルライセンスに従っています。DeepSeek-VL2シリーズは商用利用をサポートしています。
引用
@misc{wu2024deepseekvl2, title={DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding}, author={Wu, Zhiyu and Chen, Xiaokang and Pan, Zizheng and Liu, Xingchao and Liu, Wen and Dai, Damai and Gao, Huazuo and Ma, Yiyang and Wu, Chengyue and Wang, Bingxuan and Xie, Zhenda and Wu, Yu and Hu, Kai and Wang, Jiawei and Sun, Yaofeng and Li, Yukun and Piao, Yishi and Guan, Kang and Liu, Aixin and Xie, Xin and You, Yuxiang and Dong, Kai and Yu, Xingkai and Zhang, Haowei and Zhao, Liang and Wang, Yisong and Ruan, Chong}, year={2024}, }
連絡先
ご質問がございましたら、イシューを立てるか、service@deepseek.comまでご連絡ください。
aiスピーキング
ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?