ERes2Netモデルは、Res2Netの基础上で、グローバル特徴とローカル特徴をさらに融合し、話者認識性能を向上させました。ローカル特徴融合は、単一の残差ブロック内の特徴を融合してローカル信号を抽出します。グローバル特徴融合は、異なるレイヤーレベルで出力される異なるスケールの音響特徴を集約してグローバル信号を強化します。効果的な特徴融合を実現するために、ERes2Netアーキテクチャでは注目特徴融合モジュールが使用されています。
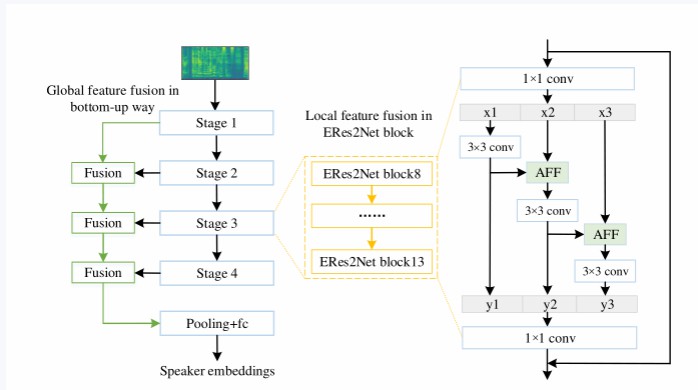
モデル概要
ERes2Netのローカル融合は下記の図の黄色部分に示されており、Attentianal feature fusionを段階的に使用して各グループの特徴を融合し、ローカル情報の接続を強化し、より細かい粒度の特徴を取得します。グローバル融合は下記の図の緑色部分に示されており、ボトムアップのグローバル特徴融合を通じて話者情報を強化します。
更に詳しい情報はこちらをご覧ください。
論文:話者検証のためのローカルとグローバル特徴融合を持つ強化されたRes2Net GitHubプロジェクトアドレス:3D-Speaker トレーニングデータ このモデルは、約200kの話者を含む大型の中国語話者データセットを使用してトレーニングされており、16kHzのサンプリングレートを持つ中国語音声を認識することができます。
モデル効果評価
CN-Celeb中国語テストセットでのEER評価結果比較:
モデル トレーニングされた話者数 CN-Celeb テスト ResNet34 約3k 6.97% ECAPA-TDNN 約3k 7.45% CAM++ 約200k 4.32% ERes2Net 約200k 2.79%
Notebookでの体験
from modelscope.pipelines import pipeline
sv_pipeline = pipeline(
task='speaker-verification',
model='damo/speech_eres2net_sv_zh-cn_16k-common',
model_revision='v1.0.5'
)
speaker1_a_wav = 'https://modelscope.cn/api/v1/models/damo/speech_campplus_sv_zh-cn_16k-common/repo?Revision=master&FilePath=examples/speaker1_a_cn_16k.wav'
speaker1_b_wav = 'https://modelscope.cn/api/v1/models/damo/speech_campplus_sv_zh-cn_16k-common/repo?Revision=master&FilePath=examples/speaker1_b_cn_16k.wav'
speaker2_a_wav = 'https://modelscope.cn/api/v1/models/damo/speech_campplus_sv_zh-cn_16k-common/repo?Revision=master&FilePath=examples/speaker2_a_cn_16k.wav'
# 同一話者の発話
result = sv_pipeline([speaker1_a_wav, speaker1_b_wav])
print(result)
# 異なる話者の発話
result = sv_pipeline([speaker1_a_wav, speaker2_a_wav])
print(result)
# スコアしきい値を設定して認識を行うことができます
result = sv_pipeline([speaker1_a_wav, speaker2_a_wav], thr=0.365)
print(result)
# output_embパラメーターを入力すると、結果に抽出された話者embeddingが含まれます
result = sv_pipeline([speaker1_a_wav, speaker2_a_wav], output_emb=True)
print(result['embs'], result['outputs'])自分のERes2Netモデルをトレーニングおよびテストする このプロジェクトでは、3D-Speakerでトレーニング、テスト、および推論コードをオープンソース化しており、以下の方法でダウンロード・インストール・使用が可能です。
git clone https://github.com/alibaba-damo-academy/3D-Speaker.git && cd 3D-Speaker
conda create -n 3D-Speaker python=3.8
conda activate 3D-Speaker
pip install -r requirements.txt
cd egs/voxceleb/sv-eres2net
# run.shでGPU情報を事前に設定する必要があります。デフォルトでは8カードを使用
bash run.shこの事前トレーニングモデルを使用してembeddingを迅速に抽出する
pip install modelscope
cd 3D-Speaker
# モデル名を設定し、wavパスを指定。wavパスは単一のwavでも、wavパスが含まれるリストファイルでも可
model_id=damo/speech_eres2net_sv_zh-cn_16k-common
# embeddingを抽出
python speakerlab/bin/infer_sv.py --model_id $model_id --wavs $wav_pathドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?

