PoNet完形填空模型-中国語-base紹介
このモデルはPoNetモデル構造を使用し、Masked Language Modeling(MLM)とSentence Structural Objective(SSO)のプリトレインタスクを通じて中国語Wikipediaデータでプリトレインされ、完形填空タスクに使用されることができ、ダウンストリームの自然言語理解タスクでファインチューンするために初期化モデルとしても使用できます。
モデルの説明
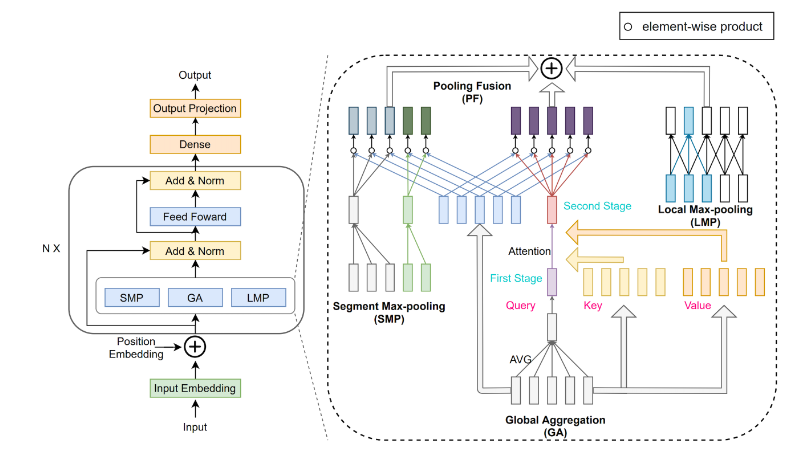
PoNetは線形複雑度(O(N))を持つ計算モデルで、Transformerモデルのself-attentionをpoolingネットワークで置き換え、文章の語彙を混合させます。具体的には、local、segment、globalの3つの粒度でのpoolingネットワークが含まれており、コンテキスト情報を捕捉します。その構造は以下の図の通りです。
PoNet
実験によると、PoNetは長文テキストテストLong Range Arena(LRA)のランキングでTransformerよりも正確性が2.28ポイント高いと同時に、GPUでの実行速度はTransformerの9倍で、ビデオメモリの使用量は1/10です。さらに、実験ではPoNetの移行学習能力も示され、PoNet-BaseはGLUE基準でBERT-Baseの95.7%の正確性を達成しました。詳細については論文「PoNet: Pooling Network for Efficient Token Mixing in Long Sequences」を参照してください。
モデルの使用方法と適応範囲
このモデルは主に完形填空の結果を生成するために使用されます。ユーザーはさまざまな入力文書を試すことができます。具体的な呼び出し方は、コードの例を参照してください。
使用方法
ModelScope-libをインストールした後、nlp_ponet_fill-mask_chinese-baseの機能を使用できます。
コードの例
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
pipeline_ins = pipeline(Tasks.fill_mask, model='damo/nlp_ponet_fill-mask_chinese-base')
input = "人民文学出版社[MASK]1952[MASK]、出版《[MASK][MASK]演义》、《[MASK]游记》、《水浒传》、《[MASK]楼梦》,合为“[MASK]大名著”。"
print(pipeline_ins(input))モデルの限界と可能性のあるバイアス
モデルのトレーニングデータが限られているため、効果に一定のバイアスが存在する可能性があります。 現在のバージョンはpytorch 1.11およびpytorch 1.12環境でテストされていますが、他の環境での可用性はテストが必要です。
トレーニングデータの紹介 データはhttps://dumps.wikimedia.org/から来ています。
モデルのトレーニングプロセス
中国語Wikipediaの無監督データでMLMおよびSSOタスクを通じてトレーニングされます。
前処理 以下の前処理がトレーニングデータで行われます。MLMタスクでは、マスクの確率は15%に設定され、80%のマスク位置が[MASK]に置き換えられ、10%はランダムにサンプリングされた単語に置き換え、残りの10%は変更されません。SSOタスクでは、複数の段落を含むシーケンスがランダムな位置で2つのサブシーケンスに切り捨てられ、そのうち1/3の確率で別のランダムに選択されたサブシーケンスに置き換えられ、1/3の確率で2つのサブシーケンスが交換され、1/3の確率で変更されません。
トレーニングの詳細
中国語WikipediaでAdamオプティマイザを使用し、初期学習率は1e-4、batch_sizeは384です。
データの評価と結果
ダウンストリームタスクでファインチューン後、CAIL、CLUEの開発セットの結果は以下の通りです。
Dataset CAIL AFQMC CMNLI CSL IFLYTEK OCNLI TNEWS WSC Accuracy 61.93 70.25 72.9 72.97 58.21 68.14 55.04 64.47
ダウンストリームタスクMUGのトピックセグメンテーションおよびトピックレベルおよびセッションレベルの抽出的要約の開発セットの結果は以下の通りです。
Task Positive F1 Topic Segmentation 0.251 Task Ave. R1 Ave. R2 Ave. RL Max R1 Max R2 Max RL Session-Level ES 57.08 29.90 38.36 62.20 37.34 46.98 Topic-Level ES 52.86 35.80 46.09 66.67 54.05 63.14 More Details: https://github.com/alibaba-damo-academy/SpokenNLP
関連する論文および引用情報 私たちのモデルが役立つ場合は、以下の論文を引用してください。
@inproceedings{DBLP:journals/corr/abs-2110-02442, author = {Chao{-}Hong Tan and Qian Chen and Wen Wang and Qinglin Zhang and Siqi Zheng and Zhen{-}Hua Ling}, title = {{PoNet}: Pooling Network for Efficient Token Mixing in Long Sequences}, booktitle = {10th International Conference on Learning Representations, {ICLR} 2022, Virtual Event, April 25-29, 2022}, publisher = {OpenReview.net}, year = {2022}, url = {https://openreview.net/forum?id=9jInD9JjicF}, } ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?