概要
Googleの研究者は、AudioPaLMと呼ばれる大規模な言語モデル(LLM)を発表しました。これはテキスト-to-スピーチ(TTS)、自動音声認識(ASR)、音声-to-音声翻訳(S2ST)を音声伝送を通じて実行できるものです。AudioPaLMは、PaLM-2 LLMに基づいており、翻訳の基準テストにおいてOpenAIのWhisper之上です。
AudioPaLMはトランスフォーマーに基づく純デコーダーモデルで、テキストと音声入力を1つの埋め込み表現に結合しています。離散ASR、機械翻訳(MT)、TTSモデルを連鎖させる伝統的なS2STモデルとは異なり、AudioPaLMは話者的音や gibiの音声学的特徴を保持できます。AudioPaLMはS2STとASRの基準テストで最先端の結果を出し、また、トレーニングデータに存在しない入力と目標の組み合わせに対してASRを実行するゼロショット能力も示しました。FLEURSデータセットで評価された際、AudioPaLMはASRタスクにおいて「顕著に」OpenAIのWhisperを上回りました。
InfoQは最近、他の多言語人工知能音声モデルも日报道しました。2022年、OpenAIは97以上の異なる言語の音声オーディオを転写と翻訳できるトランスフォーマーに基づくエンコーダー/デコーダーASRモデルであるWhisperを発表しました。今年早くに、Metaは1100以上の言語でASRとTTSを行うことができるwav2vecに基づくモデルであるMMSを発表しました。
これらと比較して、AudioPaLMはトランスフォーマーに基づく純デコーダーモデルです。事前トレーニングされたPaLM-2に基づいており、モデルのトークン辞書を音声的マーク、音声的マークは音声波形の短い断片を表し、元のモデルのテキストマークと同じ埋め込み空間にマッピングされています。その後、モデルの入力は音声とテキストを含むことができます。テキスト入力には、タスクの短い説明が含まれます(例:「[ASR イタリア語]」)。モデルの出力がデコードされると、AudioLMモデルを使用して音声的マークを音声波形に戻すことができます。
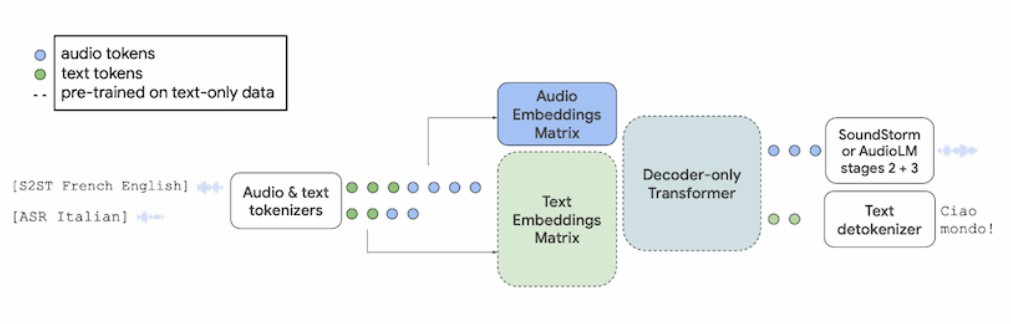
AudioPaLMのアーキテクチャ図。画像出典:https://google-research.github.io/seanet/audiopalm/examples/
AudioPaLMは100以上の言語からの数千時間の音声データでトレーニングされました。CoVoST2(AST)、CVSS(S2ST)、VoxPopuli(ASR)を含む複数の基準で評価されました。それはASTとS2STで基線モデルを上回り、ASRでは「競争力のある」結果を出しました。FLEURS基準を使用したゼロショットASTでは、AudioPaLMは「顕著著に」Whisperを上回りました。また、ASRタスクでWhisper以上の性能を発揮し、ASRタスクに関連する言語でトレーニングを受けたWhisperに対しても、AudioPaLMはその必要はありません。
研究者たちはまた、AudioPaLMの音声生成品質、特にS2ST中に元の話者の声を保持する能力も評価しました。彼らは「客観指標と主観的な評価研究」を組み合わせて、その性能を基線モデルと比較しましたが、それは「顕著に」基線を上回りました。彼らの論文では、Googleチームは音声生成品質を測定するためのより良い基準が必要であると指摘み、「テキストと比較して、生成テキスト/オーディオタスクの既存の基準セットはまだ十分に成熟していない。この仕事は主に音声認識と音声翻訳に焦点を当てており、それらは比較的に成熟した基準を持っています。生成オーディオタスクのためにもっと多くの基準と指標を確立することは、この研究をさらに加速するのに役立ちます。」
Hacker Newsの投稿でいくつかのユーザーがAudioPaLMについて議論しました。LLMの翻訳の正確実性について尋問に答えると、それは「幻覚覚」を引き起こす傾向があると指摘まれていますが、AudioPaLMのような最先端のモデルにとっては「ほとんど存在しない」と1人のユーザーは述べています。AudioPaLMの翻訳について、別のユーザーは以下のように指摘みました:
印象的です。それは「Morgenstund hat Gold im Mund」(朝は口に金が入っている)を、「早起きわみは虫を食べる」(早起きわみは虫を食べる)という対応する英語表現に翻訳しましたが、直訳ではありません。
AudioPaLMの出力をいくつかの例がオンラインで見つけることができます。
aiスピーキング
ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?

