はじめに
私たちの第一世代の推理性モデル、DeepSeek-R1-Zero と DeepSeek-R1 をご紹介します。DeepSeek-R1-Zero は、大規模な強化学習(RL)を用いて監視された微調整(SFT)を前提とせずに訓練されたモデルであり、推理性において卓越した性能を発揮しました。強化学習により、DeepSeek-R1-Zero は多くの強力で興味深い推理性行動を自然に発展させました。しかし、DeepSeek-R1-Zero は、無限の繰り返し、読みにくさ、言語の混在などに直面しています。これらの問題に対処し、推理性の性能をさらに向上させるために、RL の前にコールドスタートデータを取り入れた DeepSeek-R1 をご紹介します。DeepSeek-R1 は、数学、コード、推理性タスクにおいて OpenAI-o1 に匹敵する性能を達成しました。研究コミュニティを支援するために、DeepSeek-R1-Zero、DeepSeek-R1、および Llama と Qwen をベースにした DeepSeek-R1 から蒸留された 6 つの.dense モデルをオープンソース化しました。DeepSeek-R1-Distill-Qwen-32B は、さまざまなベンチマークで OpenAI-o1-mini を上回り、dense モデルの新しい最先端の結果を達成しています。
注意: DeepSeek-R1 シリーズのモデルをローカルで実行する前に、使用推奨セクションを確認することをお勧めします。

モデル概要
ポストトレーニング:ベースモデルにおける大規模な強化学習
私たちは、監視された微調整(SFT)を前提とせずに、強化学習(RL)を直接ベースモデルに適用しました。このアプローチにより、モデルは複雑な問題を解決するための思考の連鎖(CoT)を探索し、DeepSeek-R1-Zero の開発につながりました。DeepSeek-R1-Zero は、自己検証、反省、長い CoT の生成などの能力を示しており、研究コミュニティにとって重要なマイルストーンとなっています。特に、LLMs の推理性が純粋に RL を通じて促進され、SFT が不要であることが初めて確認されたオープンリサーチです。このブレイクスルーは、この分野の今後の発展の道を開きます。
DeepSeek-R1 の開発プロセスをご紹介します。このプロセスでは、改善された推理性パターンの発見と人間の好みとの整合性を目的とする 2 つの RL ステージ、およびモデルの推理性と非推理性能力の種となる 2 つの SFT ステージが組み込まれています。このプロセスは、より良いモデルの開発に業界が貢献すると信じています。
蒸留:小さなモデルも強力になることができます
私たちは、大きなモデルの推理性パターンが、小さなモデルで RL を通じて発見されたパターンよりも優れた性能を発揮することができる小さなモデルに蒸留されることが可能であることを示しました。オープンソースの DeepSeek-R1 とその API は、今後の小さなモデルの蒸留に研究コミュニティを支援するでしょう。
DeepSeek-R1 によって生成された推理性データを使用して、研究コミュニティで広く使用されているいくつかの.dense モデルを微調整しました。評価結果は、蒸留された小さな.dense モデルがベンチマークで非常に優れた性能を発揮することを示しています。私たちは、Qwen2.5 と Llama3 シリーズに基づく 1.5B、7B、8B、14B、32B、70B のチェックポイントをコミュニティにオープンソース化しました。
モデルのダウンロード
DeepSeek-R1 モデル
| モデル | 総パラメータ数 | 活性化パラメータ数 | コンテキスト長 | ダウンロード |
|---|---|---|---|---|
| DeepSeek-R1-Zero | 671B | 37B | 128K | 🤗 HuggingFace |
| DeepSeek-R1 | 671B | 37B | 128K | 🤗 HuggingFace |
DeepSeek-R1-Zero と DeepSeek-R1 は、DeepSeek-V3-Base をベースに訓練されています。モデルアーキテクチャの詳細については、DeepSeek-V3 リポジトリを参照してください。
DeepSeek-R1-Distill モデル
| モデル | ベースモデル | ダウンロード |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | HuggingFace |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | HuggingFace |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | HuggingFace |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | HuggingFace |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | HuggingFace |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | HuggingFace |
DeepSeek-R1-Distill モデルは、DeepSeek-R1 によって生成されたサンプルを使用してオープンソースモデルを微調整したものです。設定とトークナイザーを少し変更しています。これらのモデルを実行するには、私たちの設定を使用してください。
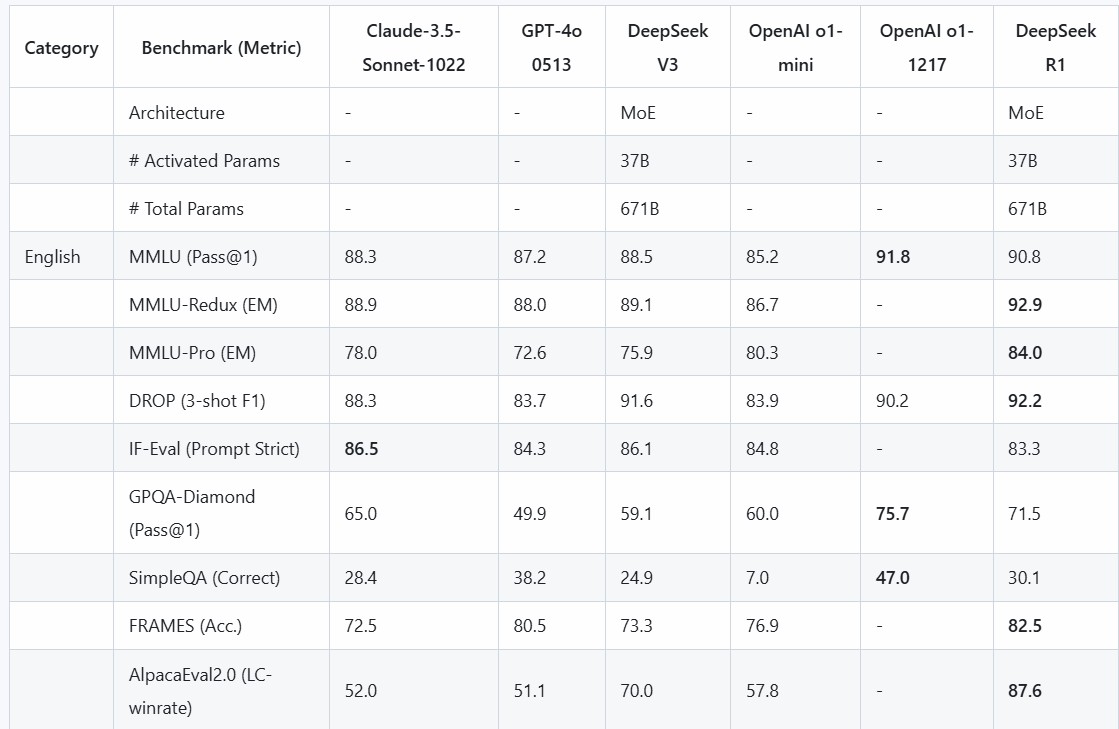
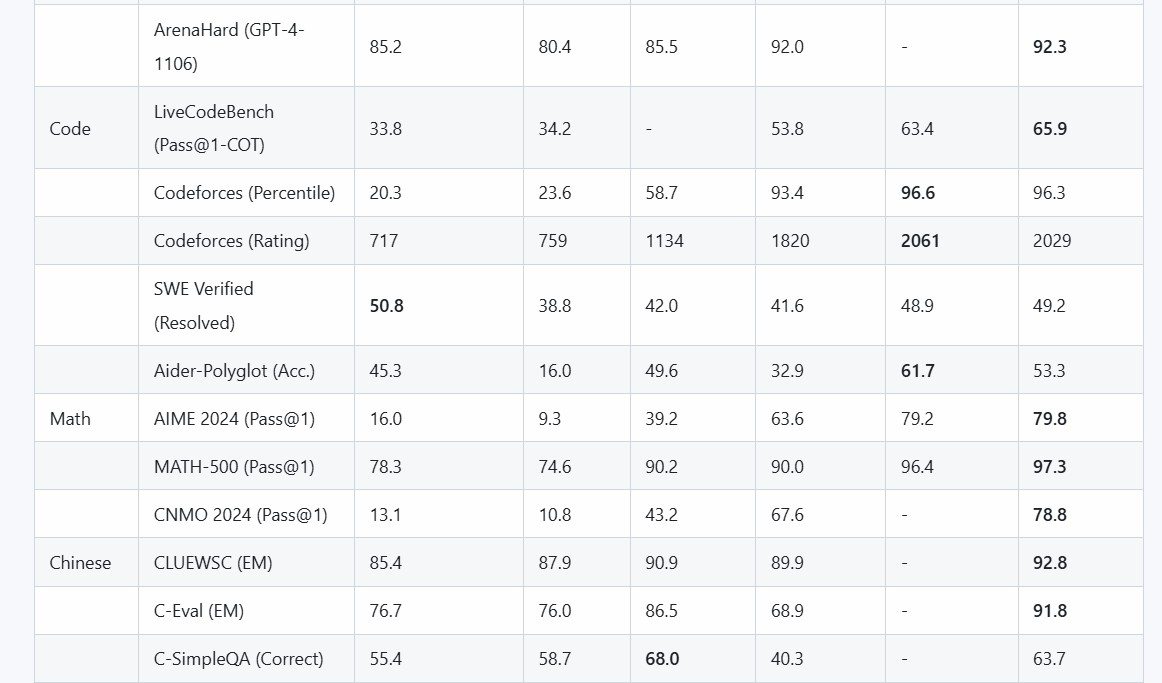
評価結果
DeepSeek-R1 評価
私たちのすべてのモデルでは、最大生成長さを 32,768 トークンに設定しています。サンプリングが必要なベンチマークでは、温度を 0.6、top-p 値を 0.95 とし、各クエリあたり 64 の応答を生成して pass@1 を推定しています。
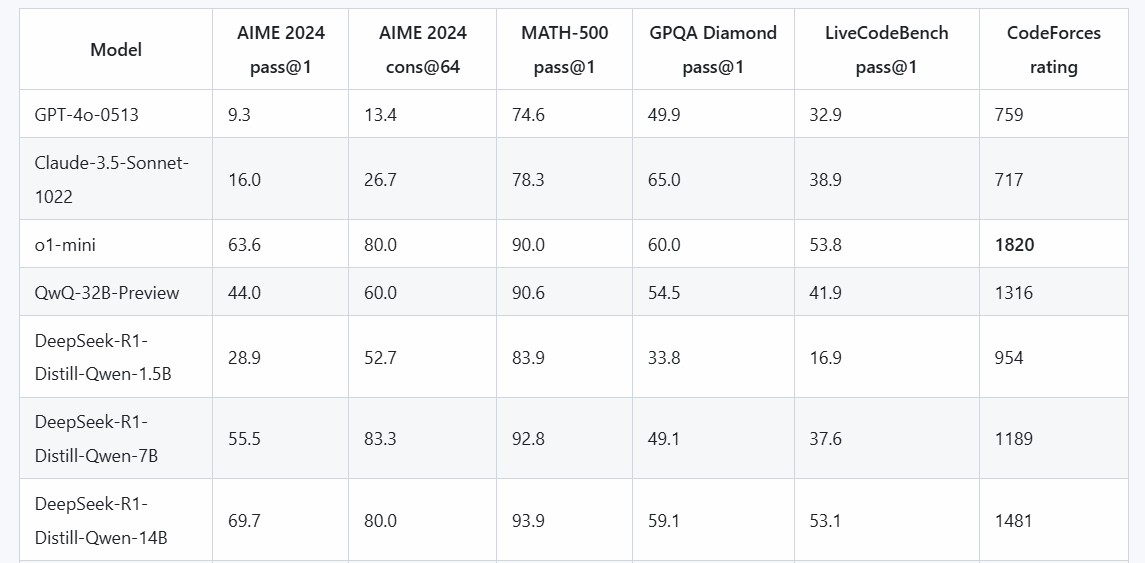
蒸留モデル評価

チャットウェブサイト & API プラットフォーム
DeepSeek-R1 でチャットするには、DeepSeek の公式ウェブサイト(chat.deepseek.com)にアクセスし、「DeepThink」ボタンをオンにしてください。
また、DeepSeek プラットフォーム(platform.deepseek.com)では、OpenAI 互換の API を提供しています。
ローカルでの実行方法
DeepSeek-R1 モデル
DeepSeek-R1 をローカルで実行する方法については、DeepSeek-V3 リポジトリを参照してください。
DeepSeek-R1-Distill モデル
DeepSeek-R1-Distill モデルは、Qwen または Llama モデルと同様に使用できます。
たとえば、vLLM を使用して簡単にサービスを開始できます:
bash复制
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
また、SGLang を使用して簡単にサービスを開始することもできます:
bash复制
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --trust-remote-code --tp 2
使用推奨
DeepSeek-R1 シリーズモデルを使用する際には、以下の設定を遵守することをお勧めします。これにより、期待される性能を発揮することができます。
-
温度を 0.5-0.7 の範囲内に設定してください(0.6 が推奨)。これにより、無限の繰り返しや不連続な出力を防ぐことができます。
-
システムプロンプトを追加しないでください。すべての指示はユーザーのプロンプト内に含めるべきです。
-
数学問題の場合、プロンプトに「Please reason step by step, and put your final answer within \boxed{}」などの指示を含めることをお勧めします。
-
モデルの性能を評価する際には、複数のテストを実施し、結果を平均化することをお勧めします。
ライセンス
このコードリポジトリとモデルのウェイトは、MIT ライセンスの下でライセンスされています。DeepSeek-R1 シリーズは、商業利用をサポートし、変更や派生作品を含む、他の LLM のための蒸留を含む、あらゆる種類の変更を許可します。ただし、以下に注意してください。
-
DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Qwen-14B、DeepSeek-R1-Distill-Qwen-32B は、元々 Apache 2.0 ライセンスの下でライセンスされている Qwen-2.5 シリーズを基にしています。現在は、DeepSeek-R1 の 800k サンプルで微調整されています。
-
DeepSeek-R1-Distill-Llama-8B は、Llama3.1-8B-Base を基にしています。元々は llama3.1 ライセンスの下でライセンスされています。
-
DeepSeek-R1-Distill-Llama-70B は、Llama3.3-70B-Instruct を基にしています。元々は llama3.3 ライセンスの下でライセンスされています。
aiスピーキング
ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?