VLDoc文書理解多モーダルプリトレインモデルの紹介
文書理解とは、視覚的に豊富な文書を自動的に分析し、処理する行為で、文書情報の抽出、文書レイアウトの分析、文書の分類、文書VQAなどが含まれます。
VLDocは文書理解用の多モーダルプリトレインモデルベースで、テキスト、ビジュアル、レイアウトの3つの文書モーダル情報を含み、文書特性に特化したプリトレインタスクを採用し、モデルが文書を十分にモデリングし、文書理解タスクの効果を高めます。
モデルの説明
モデルは双塔構造を採用し(下記の図参照)、主に3つの部分组成されます。画像バックボーンは文書の画像情報を抽出し、テキストレイアウトバックボーンは文書のテキスト、レイアウト情報をモデリングし、最後に多モーダル特徴を融合させ、関連するプリトレインタスクを接続して最適化します。
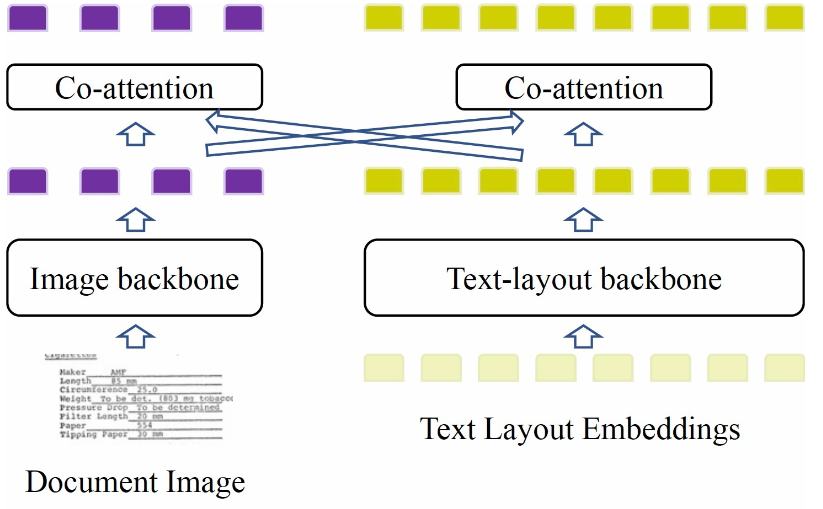
モデルの図
プリトレインタスク Masked Vision Language Modeling (MVLM)プリトレインタスクを採用します。 Bi-VLDocのText Image Position Awareness (TIPA)プリトレインタスクを採用します。 geometry pre-training tasks (from the GeoLayoutLM)を採用します。
モデルの使用方法と適応範囲
このプリトレインモデルは主に多モーダル特徴抽出のバックボーンとして、文書の多モーダル表現や文書理解関連のダウンストリームタスクのファインチューニングに使用されます。ユーザーは独自のデータを使用して呼び出すことができます。具体的な使用方法については、コードの例を参照してください。
使用方法 モデルの入力には関連するファイルdata/*が含まれるため、以下の例は本レポジトリをクローンした後、本フォルダで実行する必要があります。
コードの例
from modelscope.models import Model
from modelscope.pipelines import pipeline
model = Model.from_pretrained('damo/multi-modal_convnext-roberta-base_vldoc-embedding')
doc_VL_emb_pipeline = pipeline(task='document-vl-embedding', model=model)
inp = {
'images': ['data/demo.png'],
'ocr_info_paths': ['data/demo.json']
}
result = doc_VL_emb_pipeline(inp)
print('Results of VLDoc: ')
for k, v in result.items():
print(f'{k}: {v.size()}')
# 予想される出力:
# img_embedding: torch.Size([1, 151, 768]), 151 = 1 global img feature + 150 segment features
# text_embedding: torch.Size([1, 512, 768])
dataフォルダーの例はFUNSDからです。モデルの限界と可能性のあるバイアス
収集したデータに基づいてトレーニングされ、モデルのトレーニングデータが限られているため、効果に一定のバイアスが存在する可能性があります。
トレーニングデータの紹介
プリトレインデータ VLDocモデルのトレーニングデータセットは、インターネットから収集された文書データと一部IIT-CDIP文書データで構成され、総トレーニング文書データ数は約11Mです。 文書OCR結果は、読光OCRから提供されます。
ダウンストリームデータセット 文書情報の抽出:FUNSD, CORD, XFUND. 文書の分類:RVL-CDIP.
モデルのトレーニングプロセス この文書多モーダルプリトレインモデルは、視覚バックボーンがConvNeXtパラメーターで初期化され、テキスト+レイアウトのバックボーンがInfoXLM-baseパラメーターで初期化されます。モデルの入力画像サイズは768x768で、最大処理テキスト長は512で、超えた部分は切り捨てられます。トレーニングデータセットで自己監督プリトレイン1epochを行います。
データの評価と結果
モデル FUNSD.SER FUNSD.RE XFUND.zh.SER XFUND.zh.RE LayoutLMv3-base 0.9029 0.6684 -- -- LayoutXLM-base 0.7940 0.5483 0.8924 0.7073 VLDoc-XLM-base 0.9031 0.8259 0.9122 0.8811
関連する論文および引用情報
私たちのモデルが役立つ場合は、私たちの記事を引用してください。
@article{luo2022bi, title={Bi-VLDoc: Bidirectional Vision-Language Modeling for Visually-Rich Document Understanding}, author={Luo, Chuwei and Tang, Guozhi and Zheng, Qi and Yao, Cong and Jin, Lianwen and Li, Chenliang and Xue, Yang and Si, Luo}, journal={arXiv preprint arXiv:2206.13155}, year={2022} }
@article{cvpr2023geolayoutlm, title={GeoLayoutLM: Geometric Pre-training for Visual Information Extraction}, author={Chuwei Luo and Changxu Cheng and Qi Zheng and Cong Yao}, journal={2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year={2023} } ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?