概要
AgentRefine は、北京郵電大学とメイトゥアンが共同で提案したエージェント微調整フレームワークであり、モデルが軌道内の観測から学習して自分の誤りを訂正することにより、多様なタスクにおけるエージェントの汎化能力を大幅に向上させます。このフレームワークは、複数のエージェント評価タスクで既存の最先端の方法を上回り、強力なロバスト性和推論能力を示しました。
背景と動機
大規模言語モデル(LLMs)に基づくエージェントは、人間のように複雑なタスクを実行することができることが実証されています。環境を感知し、決定を下し、行動を取ることによって、複雑な現実世界の問題を解決する効果的なソリューションとなっています。しかし、既存のエージェントトレーニングコーパスは、トレーニング内(Held-in)評価セットでは満足できる結果を示しましたが、トレーニング外(Held-out)評価セットでは十分に汎化することができませんでした。これらのエージェントは、同じ誤りを何度も犯し、経験から学ぶことができず、既存の観測 - 行動関係を記憶するだけでした。この問題を解決するために、AgentRefine フレームワークが登場しました。その核心的な考えは、モデルが軌道内の観測から学習して自分の誤りを訂正することです。
方法
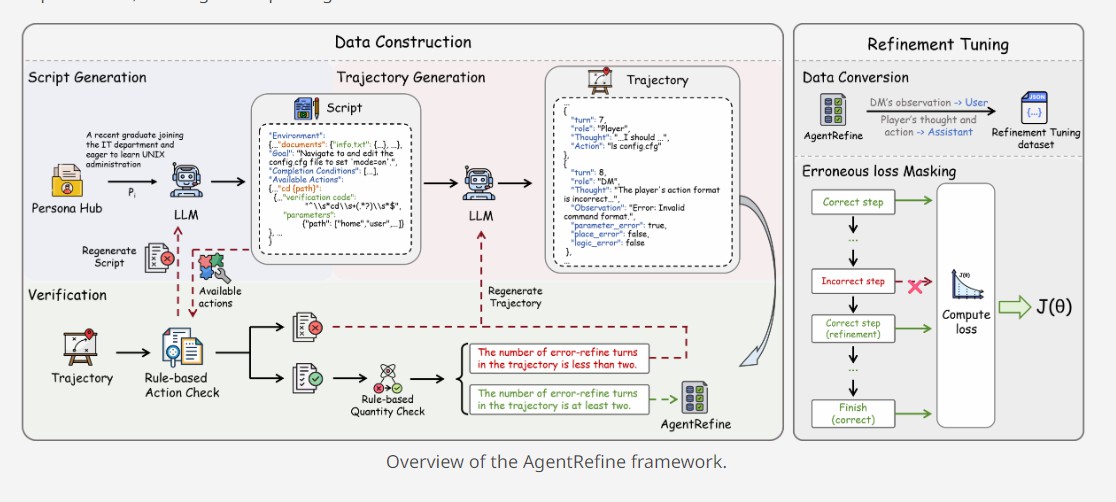
データの構築
AgentRefine のデータ構築プロセスは、テーブルロールプレイゲーム(TRPG)に触発されて、スクリプトの生成、軌道の生成、および検証の 3 つの部分に分かれています。
-
1.スクリプトの生成:多様なキャラクターから 1 つのキャラクターを抽出し、そのキャラクターに基づいて大規模言語モデルが環境、タスク、および使用可能なアクションを含むスクリプトを生成するように促します。環境には、インタラクション中に現れる可能性のある場所、アイテム、プレイヤー情報が含まれます。環境を生成した後、LLM は具体的で明確なタスクを生成し、一連の使用可能なアクションを生成します。各アクションには、アクション名、検証コード、有効なパラメーターが含まれます。
-
2.軌道の生成:スクリプトが与えられると、LLM は 1 回の呼び出しでホスト(DM)とプレイヤーの間のマルチラウンドインタラクションをシミュレートします。DM のラウンドは、思考、観測、評価の 3 つの段階に分かれています。プレイヤーのラウンドでは、LLM は現在の状態を分析して行動を提案するように求められます。
-
3.検証:検証者は、スクリプトと軌道をチェックし、LLM が与えられたキャラクターで犯した誤りを指摘します。LLM は、検証者のフィードバックに従って、スクリプト / 軌道を再生成します。
Refinement Tuning
完全な軌道が生成された後、それを Refinement Tuning データセットに変換します。ユーザーのラウンドは DM の観測であり、アシスタントのラウンドはプレイヤーの思考と行動であり、ReAct 形式で表されます。LLM が生成した誤ったラウンドが干渉しないようにするために、損失関数を変更し、誤ったラウンドに割り当てられた損失をマスクします。これにより、モデルが誤った思考プロセスを学ぶのを防ぎます。
実験
実験設定
実験では、主に LLaMA3-base シリーズのモデルと mistral-v0.3 を使用しました。5 つのタスクを選択しました:SciWorld、Alfworld、BabyAI、PDDL、Jericho。これらのタスクはすべて、モデルの決定能力をテストします。AgentBoard フレームワークを使用して実験を行い、このフレームワークはエージェントがすべてのタスクを完了したかどうか(成功率)と、エージェントが重要なノードに到達したかどうか(進行率)を判断できます。
主要な結果
AgentRefine は、多様なエージェントタスクの汎化能力において、最先端のエージェント微調整作業を大幅に上回りました。例えば、Sciworld の成功率では、Agent-FLAN を 13.3% 上回りました。注目に値的是に、いくつかのタスクでは、AgentRefine は GPT-4o シリーズの性能に匹敵することができ、その強力な汎化能力を証明しました。
ロバストネス分析
Alfworld でデータを攪乱する実験を行った結果、単純なデータ攪乱が元の held-in タスクの性能に大幅な低下をもたらすことがわかりました。AgentGym の成功率は 25.6% 下がり、Agent-FLAN の性能低下はさらに深刻で、30.4% に達しました。これに対して、AgentRefine は平均で 3.7% の増加を示し、標準偏差は低い 3.73% で、単なる記憶ではなく決定能力を学んだことを示しています。
ケーススタディ
Jericho と Sciworld における Agent-FLAN と AgentRefine の例では、Refinement Tuning がモデルの思考の多様性和品質を高め、新しい環境で常にループに陥ることなく、モデルの探索の広がりと効率を高めることができることが示されました。AgentRefine は短期記憶の複数の重要な情報を使って過去の決定における誤りを修正する能力があります。
まとめ
AgentRefine は、モデルが軌道内の観測から学習して自分の誤りを訂正することによって、多様なタスクにおけるエージェントの汎化能力を大幅に向上させます。実験結果は、AgentRefine が複数のエージェント評価タスクで既存の最先端の方法を上回り、強力なロバスト性和推論能力を示していることを示しました。この研究は、今後のエージェント研究に新たなパラダイムと方向性を提供します。
aiスピーキング
ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?

