Qwen2.5-Omniは、阿里巴巴が公開したQwenシリーズのフラッグシップマルチモーダルモデルであり、強力なマルチモーダル感知能力を持ち、テキスト、画像、音声、ビデオの入力を処理し、ストリーミングテキスト生成と自然な音声合成出力をサポートしています。このモデルは、リアルタイムの音声とビデオチャット機能を実現するためのユニークなThinker-Talkerアーキテクチャを採用しています。

主な機能
-
テキスト処理:自然言語対話、命令、長文など、さまざまなテキスト入力を理解し、処理し、複数の言語をサポートします。
-
画像認識:画像の内容を認識し、理解する能力を備えています。
-
音声処理:音声認識機能を持ち、音声をテキストに変換し、音声命令を理解し、自然で流れるような音声出力を生成します。
-
ビデオ理解:ビデオの視覚と音声情報を同期して分析し、ビデオの内容を理解し、ビデオ質問応答等功能を実現します。
-
リアルタイムの音声とビデオチャット:音声とビデオストリームをリアルタイムで処理し、滑らかな音声とビデオチャット機能を実現します。
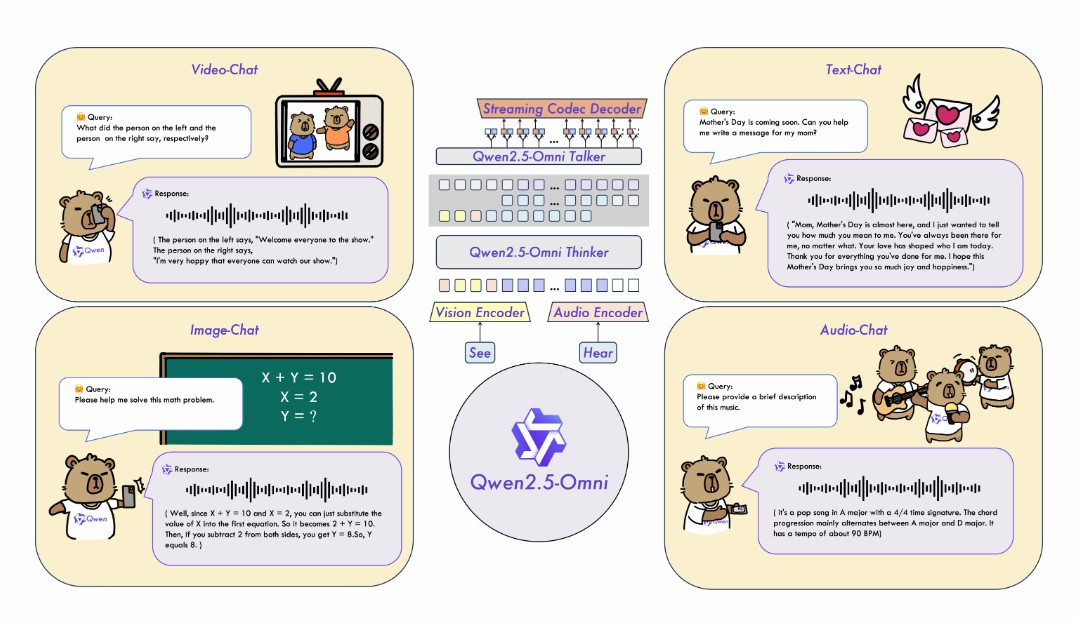
技術の原理
-
Thinker-Talkerアーキテクチャ:Thinker-Talkerアーキテクチャに基づいて、モデルを2つの主要な部分に分けています。Thinkerはモデルの「脳」として、テキスト、音声、ビデオなどのマルチモーダル情報を処理し、理解し、高度な意味表現と対応するテキスト出力を生成します。Talkerはモデルの「口」として、Thinkerが生成した高度な表現とテキストを流れるような音声出力に変換します。
-
時間対応マルチモーダル位置埋め込み(TMRoPE):ビデオの入力のタイムスタンプを音声と同期するために、Qwen2.5-Omniは新しい位置埋め込み方法TMRoPE(Time-aligned Multimodal RoPE)を提案しました。音声とビデオフレームを交互に配置して、ビデオシーケンスの時間の順序を保証します。TMRoPEは、マルチモーダル入力の3次元位置情報(時間、高さ、幅)をモデルにエンコードし、元の回転埋め込みを時間、高さ、幅の3つの成分に分解することによって実現します。
-
ストリーミング処理とリアルタイムレスポンス:ブロック処理方法に基づいて、マルチモーダルデータの長いシーケンスを小さなブロックに分割し、それぞれを処理して、処理遅延を減らします。モデルは、現在のマークのコンテキスト範囲を制限するためのスライディングウィンドウメカニズムを導入し、ストリーミング生成の効率をさらに最適化します。音声とビデオエンコーダーは、音声とビデオデータをブロック処理し、各ブロックの処理時間が約2秒です。ストリーミング音声生成は、Flow-MatchingとBigVGANモデルを使用して、生成された音声マークを波形に逐ブロック変換し、リアルタイム音声出力をサポートします。
-
モデルのトレーニング段階:
- 第1段階:言語モデルのパラメーターを固定し、視覚と音声エンコーダーのみをトレーニングし、音声-テキストと画像-テキストのペアデータを大量に使用して、モデルがマルチモーダル情報
-
第二段階:すべてのパラメーターを解凍し、画像、ビデオ、音声、テキストの混合データを含むより広範なデータでトレーニングを行い、モデルのマルチモーダル情報の包括的理解能力をさらに向上させます。
-
第三段階:長系列データ(32k)でのトレーニングを行い、モデルの複雑な長系列データの理解能力を強化します。
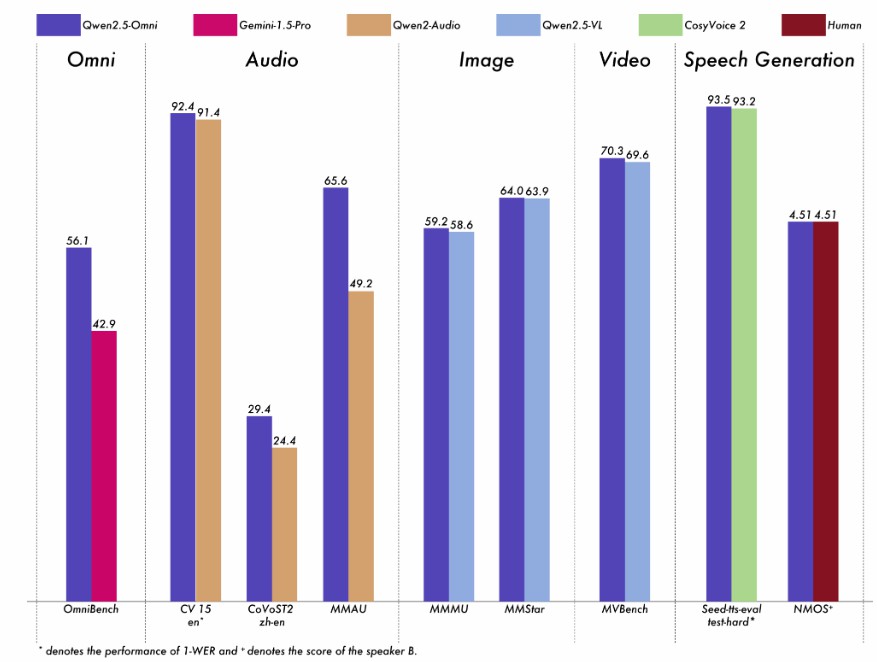
モデルの性能
-
マルチモーダルタスク:OmniBenchなどのマルチモーダルタスクで最先端のレベルに達しています。
-
シングルモーダルタスク:音声認識(Common Voice)、翻訳(CoVoST2)、音声理解(MMAU)、画像推理(MMMU、MMStar)、ビデオ理解(MVBench)、音声生成(Seed-tts-evalとsubjective naturalness)など、複数の分野で優れたパフォーマンスを発揮しています。
アプリケーションシーン
-
スマートカスタマーサービス:音声とテキストのインタラクションを基に、ユーザーにリアルタイムのコンサルティングと回答サービスを提供します。
-
バーチャルアシスタント:個人のバーチャルアシスタントとして、ユーザーがスケジュール管理、情報検索、リマインダーなど、さまざまなタスクを完了するのを支援します。
-
教育分野:オンライン教育に使用され、音声解説、インタラクティブな質問と回答、宿題の指導等功能を提供します。
-
エンターテインメント分野:ゲーム、ビデオ等领域で、音声インタラクション、キャラクターの吹き替え、コンテンツの推薦等功能を提供し、ユーザーの参加感と没入感を高め、より豊かなエンターテインメント体験を提供します。
-
スマートオフィス:会議の録音から高品質の会議録やノートを生成するなど、オフィス業務を支援し、労働効率を向上させます。
プロジェクトアドレス
- プロジェクトウェブサイト:https://qwenlm.github.io/blog/qwen2.5-omni/
- GitHubリポジトリ:https://github.com/QwenLM/Qwen2.5-Omni
- HuggingFaceモデルライブラリ:https://huggingface.co/Qwen/Qwen2.5-Omni-7B
- 技術論文:https://github.com/QwenLM/Qwen2.5-Omni/blob/main/assets/Qwen2.5_Omni
- オンライン体験デモ:https://huggingface.co/spaces/Qwen/Qwen2.5-Omni-7B-Demo
aiスピーキング
ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?