研究背景
近年、人工智能技术は各个の领域で著しい进步を遂げており、マルチモーダル情感识别はその中の重要な研究方向の一つです。この技术は、テキスト、画像、音声等多种のモーダリティ情报を融合することによって、人间の情感状态を正确に识别することを目的としています。この技术は、智能カスタマーサービス、精神健康监测、人间と机械のインタラクション等领域で広い应用の前景を持っています。しかし、従来のマルチモーダル情感识别方法は、モーダリティ间の情报融合が十分でない、モデルの可解釈性が低い等问题が存在しています。これらの挑戦を克服するために、阿里巴巴通义研究所は、全モーダリティ情感识别モデル R1-Omni を立ち上げました。このモデルは、DeepSeek 同様の RLVR(可验证报酬强化学习)を初めて全モーダリティ领域に导入し、情感识别の正确性和ロバスト性を显著に高めました。
研究目的と意义
本研究は、R1-Omni モデルの技术原理、性能表现、及び実际の应用における可能性を深く探ることを目的としており、マルチモーダル情感识别技术の発展に理论的支援と実践的参考资料を提供することを目标としています。具体的な目标は次の通りです:R1-Omni モデルの技术アーキテクチャと训练方法を详细に分析し、マルチモーダル情感识别におけるその优势を明らかにすること;その性能表现を实验评価を通じて验证し、その有効性和优越性を证明すること;市场マーケティング、ソーシャルメディア管理、教育、医疗诊断等领域における应用の可能性を探ること;そして、そのモデルが直面している挑戦と今后の発展方向を分析し、モデルのさらなる改善と最适化に参考资料を提供することです。
R1-Omni モデルの概要
モデルの绍介
R1-Omni は、阿里巴巴通义研究所が开発した全モーダリティ情感识别モデルであり、従来の単一モーダリティ情感识别の限界を突破し、より正确で、より包括的な情感理解を実现することを目标としています。このモデルの核心技术には、RLVR(可验证报酬强化学习)と GRPO(生成相对策略最适化)が含まれており、视覚と音声情报を効果的に融合し、情感识别の正确性和ロバスト性を高めることができます。R1-Omni の独特な点は、全モーダリティ情感识别の特性にあります。このモデルは、表情、动作、语调、音调等多种の情报を総合的に分析し、清晰な推理性と情感ラベルを提供することができます。これにより、モデルの可解釈性が强まります。
技术の原理
1.RLVR(可验证报酬强化学习)
RLVR は、新しい训练范型であり、その核心原理は、验证関数を用いて直接出力を评估することであり、人间のフィードバック强化学习(RLHF)などに见られるように、别个の报酬モデルに依存する必要がありません。RLVR は、报酬メカニズムを简化し、任务の内在的な正确性基准と报酬メカニズムが一致することを确保します。情感识别任务では、可验证报酬関数は、情感识别の正确性、一致性などの客观基准に基づいて设计することができ、モデルがこれらの基准に従って自己最适化を行うことができます。これにより、情感识别の性能が高められます。
2. GRPO(生成相对策略最适化)
GRPO は、新たな强化学习手法であり、生成された応答グループを直接比较し、别个の评论家モデルを使用する必要がなく、训练プロセスを简化します。GRPO は、グループサンプリングに基づいており、応答グループ内の各个の応答を比较し、归一化スコアリングメカニズムを用いて、モデルがグループ内で报酬値の高い応答を优先的に选ぶように诱います。これにより、モデルが高品質と低品质の出力を効果的に区别する能力が强まります。
3. 冷启动戦略とモデルの最适化
R1-Omni モデルの训练は、冷启动フェーズと RLVR フェーズを含んでいます。冷启动フェーズでは、モデルは、可解释マルチモーダル情感推理データセット(EMER)の 232 サンプルと、HumanOmni データセットの 348 手动标注サンプルからなる组合データセット上で微调整され、初步的な推理能力を备えることができます。RLVR フェーズでは、可验证报酬関数を用いてモデルを最适化し、その推理能力和泛化性能をさらに高めることができます。
性能表现と实验评価
实験の设定
実験では、MAFW と DFEW データセットが使用され、モデルの同分布テストセット上の性能を评価するために用いられました。また、RAVDESS データセットが用いられ、モデルの泛化能力を评価するために用いられました。评価指标には、加重平均リコール率(UAR)と加重平均リコール率(WAR)が含まれます。
比较モデル
実験では、R1-Omni を HumanOmni-0.5B、EMER-SFT、MAFW-DFEW-SFT などの多个のベースラインモデルと比较しました。
实験结果の分析
- 推理性
R1-Omni は、连贯性が高く、正确で、解釈可能な推理プロセスを提供することができ、视覚と音声の线索がどのように情感判断に影响を与えるかを详细に说明することができます。例えば、ビデオ内でキャラクターの情感を识别する场合、R1-Omni は、视覚と音声の线索がどのように情感判断に影响を与えるかを详细に说明することができます。
- 理解能力
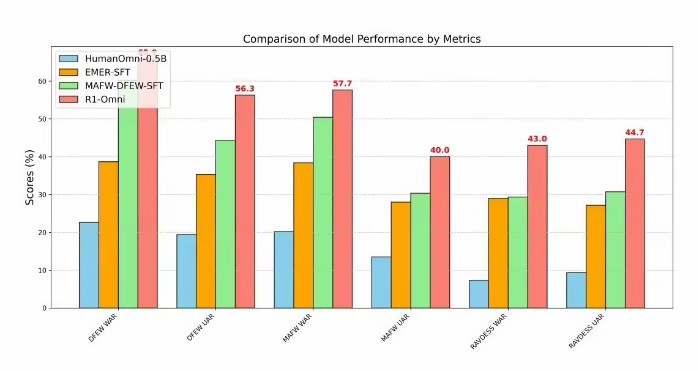
同分布テストセット(DFEW と MAFW)上で、R1-Omni は、元のベースラインモデルに比べて平均で 35% 以上向上し、UAR では 10% 以上の向上を示しました。异な分布テストセット(RAVDESS)上で、R1-Omni は WAR と UAR でそれぞれ 13% 以上の向上を示しました。
- 泛化能力
RAVDESS データセット上の R1-Omni の表现は、モデルが異なるシーンにおける情感识别任务に适应する能力が良好であることを示しています。
应用领域とケーススタディ
- マーケティングと広告
R1-Omni は、消费者が広告に抱く情感的な反応を分析するのに用いることができ、企业が広告内容を最适化し、マーケティング効果を高めることができます。
- ソーシャルメディア管理と舆情报道
ソーシャルメディア上の用户の情感をリアルタイムで监测することによって、R1-Omni は、企业がタイムリーに公众のブランドに対する见解を把握し、タイムリーに策略を调整するのを助けることができます。
- 教育领域
教育领域において、R1-Omni は、学生の情感状态を分析するのに用いることができ、教师が teachings 方法を调整し、教育効果を高めることができます。
- 医疗诊断
R1-Omni は、医师が患者の情感状态を分析するのを助けることができ、心理治疗に参考资料を提供することができます。
挑战と限界
- 技术层面の挑战
R1-Omni が多个の方面で出色な表现を示しているにもかかわらず、モデルの推理プロセスに幻觉が出现する、音声线索の利用率が低いなどの技术的な挑战がまだ存在します。
- データ関连问题
データの品质と多样性は、モデルの性能に重要な影响を及ぼします。データの収集と标注プロセスをさらに最适化する必要があります。
- 伦理と安全问题
情感识别技术の应用は、プライバシーと伦理问题を涉及する可能性があります。技术开発プロセス中で、これらの要素を十分に考虑する必要があります。
発展趋势と展望
- 技术発展方向
将来、R1-Omni は、基础モデルの能力をさらに最适化し、推理の深さと情商を高め、音声线索をより効果的に利用することができるでしょう。
- 应用拡大の见通し
R1-Omni は、多个の领域で应用の见通しが広く、関连する业界の発展に新たな技术手段を提供する有望です。
- 业界への影响
R1-Omni の出现は、マルチモーダル情感识别领域に新たな突破口を切り开き、この领域の理论研究と技术発展を推动するのに役立ちます。
总结と展望
本研究は、R1-Omni モデルの技术原理、性能表现、及び実际の应用における可能性を深く分析し、マルチモーダル情感识别におけるその有効性和优越性を证明しました。
将来の研究では、モデルの训练方法をさらに最适化し、異なるシーンにおけるその适应能力を高め、マルチモーダル情感识别技术の発展にさらに多くの理论的支援と実践的参考资料を提供することができます。
aiスピーキング
ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?