一、はじめに
pipeline(パイプライン)は、huggingface transformersライブラリで提供される極めてシンプルな大規模モデル推論の抽象化であり、すべての大規模モデルをオーディオ(Audio)、コンピュータビジョン(Computer vision)、自然言語処理(NLP)、マルチモーダル(Multimodal)などの4つの大カテゴリ、28のサブタスクに分類し、計32万モデルをカバーしています。

今日はオーディオ音声の第二弾として、自動音声認識(automatic-speech-recognition)について紹介します。huggingfaceライブラリには、1.8万个のオーディオ分類モデルがあります。
二、自動音声認識(automatic-speech-recognition)
2.1 概要
自動音声認識(ASR)、または音声をテキストに変換(STT)とは、与えられた音声をテキストに転写するタスクです。主なアプリケーションシーンには人間とコンピュータの対話、音声からテキストへの変換、歌詞認識、字幕生成などが含まれます。
2.2 技術原理
自動音声認識の主な原理は、オーディオを25ms-60msの音谱に分割し、畳み込みネットワークを使用してオーディオ特徴を抽出し、次にTransformerなどのネットワーク構造でテキストと連携してトレーニングします。比較的有名な自動音声認識には、openaiのwhisperとmetaのWav2vec 2.0が挙げられます。
2.2.1 whisperモデル
音声部分:680000時間のオーディオデータでトレーニングされ、英語、他の言語から英語への翻訳、非英語などを含む多言語が含まれます。オーディオデータをメル頻谱図に変換し、2つの畳み込み層を通過させてからTransformerモデルに送ります。
テキスト部分:テキストトークンは3つのカテゴリがあります:special tokens(特別トークン)、text tokens(テキストトークン)、timestamp tokens(タイムスタンプ)。特別トークンを使用してテキストの開始と終了を制御し、タイムスタンプトークンを使用して音声時間とテキストを照合します。
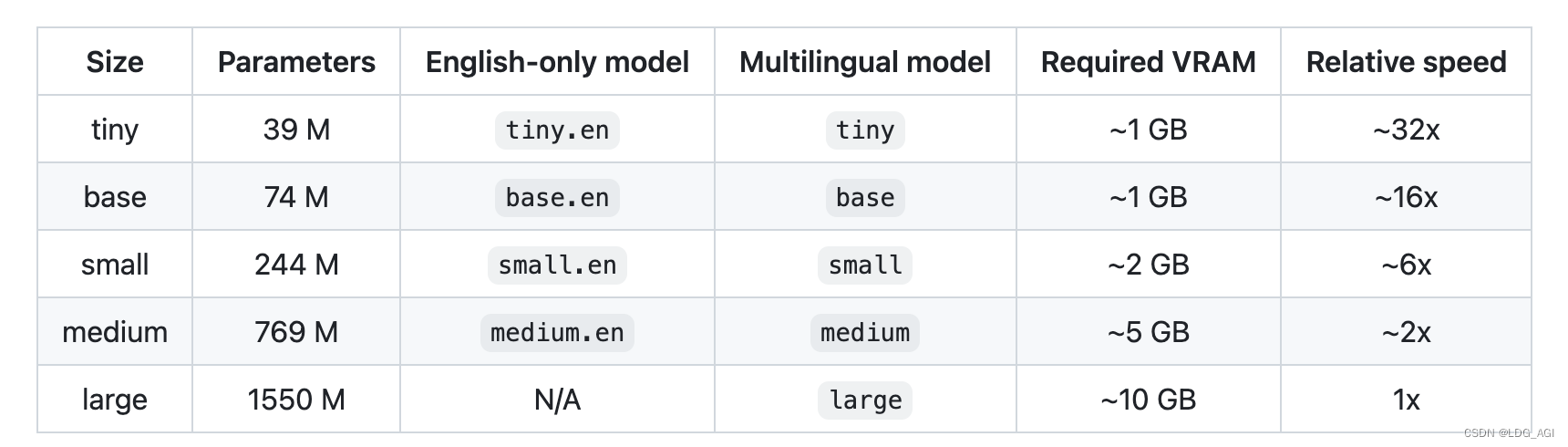
異なるサイズのモデルパラメータ、多言語サポート状況、必要なメモリサイズ、および推論速度は以下の通りです。
2.2.2 Wav2vec 2.0モデル
Wav2vec 2.0は、Metaが2020年に発表した無監督音声プリトレーニングモデルです。そのコアコンセプトは、ベクトル量子化(Vector Quantization、VQ)を用いて自己構築の監督トレーニング目標を構築し、大量のマスクを適用した後、比較学習損失関数を使用してトレーニングします。モデル構造は図のように、畳み込みネットワーク(Convolutional Neural Network、CNN)の特徴抽出器が生のオーディオをフレーム特徴系列にエンコードし、VQモジュールで各フレーム特徴を離散特徴Qに変換し、自己監督目標として扱います。同時に、フレーム特徴系列にマスク操作を施した後、Transformer [5] モデルを介して文脈表現Cを得ます。最後に、比較学習損失関数を用いて、マスクされた位置の文脈表現と対応する離散特徴qの距離を近づけます。
2.3 pipelineパラメータ
2.3.1 pipelineオブジェクトインスタンス化パラメータ
- モデル( PreTrainedModel または TFPreTrainedModel)— パイプラインが予測に使用するモデル。PyTorchの場合、これは PreTrainedModelから継承される必要があります。TensorFlowの場合、これは TFPreTrainedModelから継承される必要があります。
- feature_extractor( SequenceFeatureExtractor)— パイプラインが波形の特徴をエンコードするために使用する特徴抽出器。
- tokenizer ( PreTrainedTokenizer ) — パイプラインがデータをエンコードするために使用するtokenizer。このオブジェクトは PreTrainedTokenizerから継承されます。
- デコーダー(
pyctcdecode.BeamSearchDecoderCTC、オプション)— PyCTCDecodeのBeamSearchDecoderCTCを渡して言語モデル強化デコーディングに使用できます。詳細については、Wav2Vec2ProcessorWithLM を参照してください。 - chunk_length_s (
float、オプション、デフォルトは 0) — 各チャンクの入力長さ。chunk_length_s = 0でチャンクを無効にします(デフォルト)。 - stride_length_s (
float、オプション、デフォルトはchunk_length_s / 6) — 各チャンクの左側と右側のストライド長さ。chunk_length_s > 0と共にのみ使用されます。これによりモデルはより多くの文脈を“見る”ことができ、文脈なしよりも文字をより適切に推測できますが、パイプラインは最終的な重建をできるだけ完璧にするために、ストライド位置を最後まで削除します。 - フレームワーク(
str、オプション)— 使用するフレームワーク、"pt"はPyTorch、"tf"はTensorFlowに適用されます。指定されたフレームワークをインストールする必要があります。フレームワークが指定されていない場合、デフォルトでは現在インストールされているフレームワークになります。両方のフレームワークがインストールされている場合、modelのフレームワークがデフォルトになります。モデルが指定されていない場合は、PyTorchのフレームワークがデフォルトになります。 - デバイス(Union[
int,torch.device]、オプション)— CPU/GPUをサポートするデバイスの数。Noneに設定するとCPUが使用されます。正の数に設定すると、関連するCUDAデバイスIDでモデルが実行されます。 - torch_dtype (Union[
int,torch.dtype], オプション) — 計算に使用するデータタイプ(dtype)。Noneに設定するとfloat32精度が使用されます。torch.float16またはtorch.bfloat16に設定すると、対応するdtypeで半精度を使用します。
2.3.2 pipelineオブジェクト使用パラメータ
- 入力(
np.ndarrayまたはbytesまたはstrまたはdict)— 入力は以下のいずれかです:str即ち、ローカルオーディオファイルのファイル名、またはオーディオファイルをダウンロードするパブリックURL。ファイルは正しいサンプリングレートで読み取られ、_ffmpeg_を使用して波形を取得します。これはシステムに_ffmpegがインストールされている必要があります。bytesはオーディオファイルの内容であり、同じ方法で_ffmpegによって解釈されます。- (
np.ndarray形状は(n,)型はnp.float32またはnp.float64)正しいサンプリングレートの生のオーディオ(さらなるチェックなし) dictは任意のサンプリングの生のオーディオsampling_rateを渡し、このパイプラインがリサンプリングを行うことができます。辞書は{"sampling_rate": int, "raw": np.array}の形式で、オプション形式"stride": (left: int, right: int)で、パイプラインがデコード時に最初のleftサンプルと最後のrightサンプルを無視することを要求することができます(しかし、モデルがより多くの文脈を提供するために推論時に使用されます)。CTCモデルにのみ適用されます。
-
return_timestamps( オプション、
strまたはbool)— 純粋なCTCモデル(Wav2Vec2、HuBERTなど)とWhisperモデルにのみ適用されます。他のシケンストシーケンスモデルには適用されません。 CTCモデルの場合、タイムスタンプは以下の2つの形式のいずれかを採用できます:"char":パイプラインはテキストの各文字のタイムスタンプを返します。たとえば、[{"text": "h", "timestamp": (0.5, 0.6)}, {"text": "i", "timestamp": (0.7, 0.9)}]を得ると、モデルが文字“h”を0.5秒後0.6秒前に話したと予測したことを意味します。"word":パイプラインはテキストの各単語のタイムスタンプを返します。たとえば、[{"text": "hi ", "timestamp": (0.5, 0.9)}, {"text": "there", "timestamp": (1.0, 1.5)}]を得ると、モデルが単語“hi”を0.5秒後0.9秒前に話したと予測したことを意味します。
Whisperモデルの場合、タイムスタンプは以下の2つの形式のいずれかを採用できます:
"word":上記と同じで、文字レベルCTCタイムスタンプに適用されます。文字レベルタイムスタンプは、交叉注意重みをチェックすることで近似的に予測される_動的時間規整化(DTW)_アルゴリズムを使用します。True:パイプラインはテキストの単語_フラグメント_のタイムスタンプを返します。たとえば、[{"text": " Hi there!", "timestamp": (0.5, 1.5)}]を得ると、モデルが“Hi there!”フラグメントを0.5秒後1.5秒前に話したと予測したことを意味します。请注意、テキストフラグメントは1つまたは複数の単語のシーケンスを指し、単語レベルタイムスタンプのような単一の単語ではありません。
- generate_kwargs(
dict、オプションgenerate_config)— 生成呼び出しに使用される一時的なパラメーター化辞書。generateの詳細については、以下のガイドを参照してください。 - max_new_tokens(
int、オプション)— 生成される最大トークン数、プロンプト内のトークン数は無視されます。
2.3.3 pipelineオブジェクト戻りパラメータ
- テキスト(
str):認識されたテキスト。 - chunks( オプション(、
List[Dict])return_timestampsを使用時、MARKDOWN_HASHa0e6aa3f5109dc15b489f628b2f01028MARKDOWNHASHはモデルによって認識されたすべてのテキストチャンクのリストになり、 たとえば\*[{"text": "hi ", "timestamp": (0.5, 0.9)}, {"text": "there", "timestamp": (1.0, 1.5)}]。元の全文を粗略に復元するには"".join(chunk["text"] for chunk in output["chunks"])を実行できます。
2.4 pipeline実践
2.4.1 facebook/wav2vec2-base-960h(デフォルトモデル)
pipelineのautomatic-speech-recognitionのデフォルトモデルはfacebook/wav2vec2-base-960hで、pipelineを使用する場合、task=automatic-speech-recognitionのみを設定し、モデルを設定しない場合は、デフォルトモデルがダウンロードされ使用されます。
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
from transformers import pipeline
speech_file = "./output_video_enhanced.mp3"
pipe = pipeline(task="automatic-speech-recognition")
result = pipe(speech_file)
print(result).mp3内の音声をテキストに変換できます。
{'text': "WELL TO DAY'S STORY MEETING IS OFFICIALLY STARTED SOMEONE SAID THAT YOU HAVE BEEN TELLING STORIES FOR TWO OR THREE YEARS FOR SUCH A LONG TIME AND YOU STILL HAVE A STORY MEETING TO TELL"}2.4.2 openai/whisper-medium
モデルopenai/whisper-mediumを指定します。具体的なコードは以下の通りです。
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
from transformers import pipeline
speech_file = "./output_video_enhanced.mp3"
pipe = pipeline(task="automatic-speech-recognition", model="openai/whisper-medium")
result = pipe(speech_file)
print(result)入力はmp3形式の音声で、出力は
{'text': " Well, today's story meeting is officially started. Someone said that you have been telling stories for two or three years for such a long time, and you still have a story meeting to tell."}2.5 モデルランキング
huggingfaceでは、自動音声認識モデルを絞り込み、ダウンロード数順に並べ替えます。
三、まとめ
本記事では、TransformersのPipelineの自動音声認識(automatic-speech-recognition)について、概要、技術原理、Pipelineパラメータ、Pipeline実践、モデルランキングから紹介しました。読者はPipelineを使用して、文中のコードを极简に自動音声認識推論を行うことができ、音声認識、字幕抽出などのビジネスシーンに適用できます。
aiスピーキング
ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?

