はじめに
私たちは興奮しさでQwen2-VL、私たちのQwen-VLモデルの最新イテレーションを公開します。これはほぼ1年の革新を象徴しています。
Qwen2-VLで新しいものは何ですか?
主要な強化点:
-
SoTA 图像理解能力の向上、様々な解像度&比率:Qwen2-VLはMathVista、DocVQA、RealWorldQA、MTVQAなど、視覚理解のベンチマークで最先端のパフォーマンスを達成しています。
-
20分以上のビデオの理解:Qwen2-VLは20分以上のビデオを理解し、高品質なビデオベースの質問回答、対話、コンテンツ作成などに使用できます。
-
モバイル、ロボットなどの操作可能:複雑な推理以及意思決定能力を持ち、Qwen2-VLはスマートフォン、ロボットなどのデバイスと統合され、視覚環境以及テキスト指示に基づく自動操作が可能です。
-
多言語対応:世界的にユーザーをサービスし、英語および中国語に加えて、Qwen2-VLは今、画像内の異なる言語のテキストの理解をサポートしており、ほとんどのヨーロッパ語、日本語、韓国語、アラビア語、ベトナム語などを含みます。
モデルアーキテクチャー更新:
-
Naive 動的解像度:以前とは異なり、Qwen2-VLは任意の画像解像度を扱い、それらを動的解像度数の視覚的トークンにマッピングし、人間の視覚的処理経験に近い提供をします。
-
多モーダルロータリーポジション埋め込み(M-ROPE):位置埋め込みを1次元テキスト、2次元視覚的、3次元ビデオ的位置情報を捉えるように分解し、多モーダル処理能力を強化します。
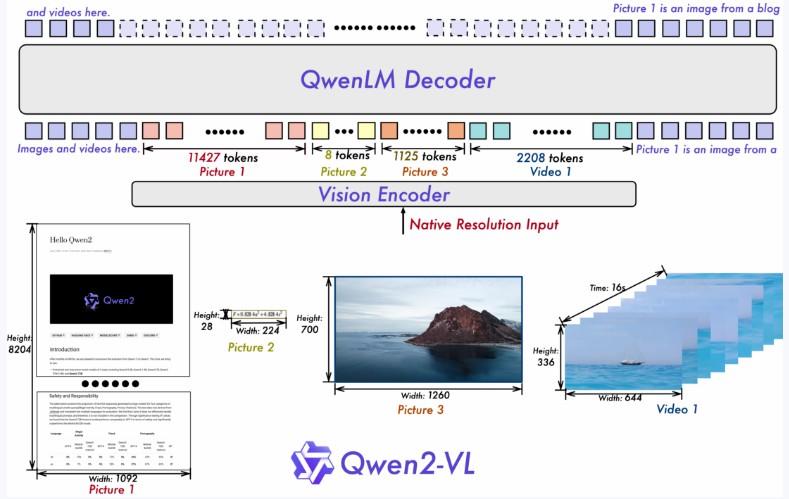
私たちは2億、7億、72億パラメータの3つのモデルを持っています。このレポは指示調整された7B Qwen2-VLモデルを含んでいます。詳細については、私たちのブログ以及GitHubを訪れください。
評価
画像ベンチマーク
| ベンチマーク | InternVL2-8B | MiniCPM-V 2.6 | GPT-4o-mini | Qwen2-VL-7B |
|---|---|---|---|---|
| MMMUval | 51.8 | 49.8 | 60 | 54.1 |
| DocVQAtest | 91.6 | 90.8 | - | 94.5 |
| InfoVQAtest | 74.8 | - | - | 76.5 |
| ChartQAtest | 83.3 | - | - | 83.0 |
| TextVQAval | 77.4 | 80.1 | - | 84.3 |
| OCRBench | 794 | 852 | 785 | 845 |
| MTVQA | - | - | 26.3 | - |
| RealWorldQA | 64.4 | - | - | 70.1 |
| MMEsum | 2210.3 | 2348.4 | 2003.4 | 2326.8 |
| MMBench-ENtest | 81.7 | - | - | 83.0 |
| MMBench-CNtest | 81.2 | - | - | 80.5 |
| MMBench-V1.1test | 79.4 | 78.0 | 76.0 | 80.7 |
| MT-Benchtest | - | - | 63.7 | - |
| MMStar | 61.5 | 57.5 | 54.8 | 60.7 |
| MMVetGPT-4-Turbo | 54.2 | 60.0 | 66.9 | 62.0 |
| HallBenchavg | 45.2 | 48.1 | 46.1 | 50.6 |
| MathVistatestmini | 58.3 | 60.6 | 52.4 | 58.2 |
| MathVision | - | - | 16.3 | - |
ビデオベンチマーク
| ベンチマーク | InternVL2-8B | LLaVA-OneVision-7B | MiniCPM-V 2.6 | Qwen2-VL-7B |
|---|---|---|---|---|
| MVBench | 666.4 | 56.7 | - | 67.0 |
| PerceptionTesttest | - | 57.1 | - | 62.3 |
| EgoSchematest | - | 60.1 | - | 6.7 |
| Video-MMEwo/w subs | 54.0/56.9 | 58.2/- | 60.9/63.6 | 63.3/69.0 |
要件
Qwen2-VLのコードは、最新のHugging face transformersに含まれており、pip install git+https://github.com/huggingface/transformers でソースからビルドをお勧めことをお勧めします。そうでない場合は、以下のエラーが発生する可能性があります:
KeyError: 'qwen2_vl' クイックスタート 私たちは、APIを使用しているかのように、さまざまなタイプの視覚的入力をより便利に処理するためのツールキットを提供しています。これにはbase64、URL、および交差画像およびビデオが含まれます。以下のコマンドでインストールできます:
pip install qwen-vl-utils ここでは、transformersおよびqwen_vl_utilsを使用してチャットモデルをどのように使用するかを示すコードスニペットを示します:
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
from modelscope import snapshot_download
model_dir = snapshot_download("qwen/Qwen2-VL-7B-Instruct")
# デフォルト:使用可能なデバイスにモデルをロード
model = Qwen2VLForConditionalGeneration.from_pretrained(
model_dir, torch_dtype="auto", device_map="auto"
)
# より良い加速化とメモリ節約のため、flash_attention_2を有効にすることをお勧めします。特に多画像以及ビデオシナリオで。
# model = Qwen2VLForConditionalGeneration.from_pretrained(
# model_dir,
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# デフォルトプロセッサー
processor = AutoProcessor.from_pretrained(model_dir)
# デフォルトでは、モデル内の画像ごとの視覚的トークン数は4-16384の範囲です。必要に応じてmin_pixelsおよびmax_pixelsを設定し、256-1280のトークン数範囲など、速度とメモリ使用量的バランス取る設定が可能です。
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained(model_dir, min_pixels=min_pixels, max_pixels=max_pixels)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "この画像について説明してください。"},
],
}
]
# 推論の準備
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# 推論:出力の生成
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)qwen_vl_utilsなし 多画像推論 ビデオ推論 バッチ推論 詳細な使用方法のヒント 画像入力而言、私たちはローカルファイル、base64、およびURLをサポートしています。ビデオ而言、現在はローカルファイルのみをサポートしています。
テキストの位置にローカルファイルパス、URL、またはbase64エンコードされた画像を直接挿入できます。
ローカルファイルパス messages = [ { "role": "user", "content": [ {"type": "image", "image": "file:///path/to/your/image.jpg"}, {"type": "text", "text": "この画像について説明してください。"}, ], } ]
画像URL
messages = [ { "role" : "user", "content": [ {"type": "image", "image": "http://path/to/your/image.jpg"}, {"type": "text", "text": "この画像について説明してください。"}, ], } ]
base64エンコードされた画像
messages = [ { "role": "user", "content": [ {"type": "image", "image": "data:image;base64,/9j/..."}, {"type": "text", "text": "この画像について説明してください。"}, ], } ]
パフォーマンス向上のための画像解像度
モデルは広範な解像度入力をサポートしています。デフォルトでは、入力にネイティブな解像度を使用しますが、より高い解像度は計算コストを付出してパフォーマンスを向上させることができます。ユーザーは最小および最大ピクセル数を設定し、256-1280のトークン数範囲など、速度以及メモリ使用量のバランス取る最適切な設定を実現できます。
min_pixels = 256 28 28 max_pixels = 1280 28 28 processor = AutoProcessor.from_pretrained( model_dir, min_pixels=min_pixels, max_pixels=max_pixels ) また、モデルへの画像サイズ入力を細かく制御するための2つの方法を提供しています:
最小ピクセル数以及最大ピクセル数を定義:画像は最小ピクセル数以及最大ピクセル数の範囲内でアスペクト比を維持しながらリサイズ調整されます。
正確な寸法を指定:resized_height以及resized_widthを直接設定します。これらの値は28の近隣接倍数に丸められます。
min_pixelsおよびmax_pixels
messages = [ { "role": "user", "content": [ { "type": "image", "image": "file:///path/to/your/image.jpg", "resized_height": 280, "resized_width": 420, }, {"type": "text", "text": "この画像について説明してください。"}, ], } ]
resized_heightおよびresized_width
messages = [ { "role": "user", "content": [ { "type": "image", "image": "file:///path/to/your/image.jpg", "min_pixels": 50176, "max_pixels": 50176, }, {"type": "text", "text": "この画像について説明してください。"}, ], } ]
制限事項
Qwen2-VLは視覚的タスクの広範な範囲に適用可能ですが、その制限も理解することが同等に重要です。以下はいくつかの既知られた制限です:
音声のサポート不足:現在のモデルはビデオ内の音声情報를 이해하지 못합니다。 データのタイムライン:私たちの画像データセットは2023年6月まで更新されており、その後の情報がカバーされているとは限りません。 個人以及知的財産(IP)の制約:モデルは特定の個人またはIPを認識する能力が限定されており、すべての有名な人物またはブランドを完全にカバーすることはできません。 複雑な指示への対応能力の不足:複雑な多段階の指示に対処する際、モデルの理解力以及実行能力が向上が必要です。 数え数の正確性の不足:特に複雑なシーンでは、オブジェクト数えの正確性が高くないため、さらなる改善が必要です。 空間的推論力の弱さ:特に3D空間では、モデルのオブジェクト位置関係の推論が不十分であり、オブジェクトの相対的な位置を正確に判断することが困難しくなります。 これらの制限はモデルの最適化以及改善の進行方向を示しており、私たちはモデルのパフォーマンス以及応用範囲の継続的な向上に尽力しています。
引用
私たちの仕事が役に立ったら、引用してください。
@article{Qwen2-VL,
title={Qwen2-VL},
author={Qwen team},
year={2024}
}
@article{Qwen-VL,
title={Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond},
author={Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren},
journal={arXiv preprint arXiv:2308.12966},
year={2023}
}aiスピーキング
ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?


{kind=link}