オムニビジョン
🔥 最新アップデート [2024年11月22日] メジャーモデル改善:OmniVision v2モデルのGGUFファイルがこのHugging Face Repoで更新されました!✨ 主な改善点は以下の通りです: アート説明の強化 複雑な画像理解の改善 アニメ認識の向上 より正確な色と詳細の検出 世界知識の拡大 👉 これらのエキサイティングな変更をHugging Face Spaceでテストしてください。
貴重なフィードバックに基づいて、Omnivision-968Mを絶えず改善しています!さらにエキサイティングなアップデートがすぐに到来します - 調整してください!⭐
はじめに
オムニビジョンは、視覚とテキスト入力を処理するコンパクトで亜億(968M)マルチモーダルモデルで、エッジデバイスに最適化されています。LLaVAのアーキテクチャを改善し、以下の特徴があります:
9倍のトークン削減:画像トークンを729から81に削減し、レイテンシーと計算コストを激減させます。視覚エンコーダと投影部の計算は同じですが、言語モデルバックボーンの計算は、画像トークンの長さが9倍短縮されるため減少します。 信頼できる結果:信頼できるデータからのDPOトレーニングを使用して、幻觉を減らします。 クイックリンク:
Hugging Face Spaceのインタラクティブデモ。(2024年11月21日更新) ローカルセットアップのためのクイックスタート ブログでもっと学ぶ フィードバック:Discordでモデルに関する質問やコメントを送信してください
意図した使用事例
オムニビジョンは、画像についての質問に答えたり、写真のシーンを説明する画像キャプション(Visual Question Answering)に適しており、デバイス上のアプリケーションに理想的です。
デモ例:M4 Pro Macbookで1046×1568ピクセルの画像にキャプションを生成すると、処理時間が2秒未満で、RAMは988MB、ストレージは948MBしか必要ありません。
ベンチマーク
下記の図では、オムニビジョンがnanollavaとどのように対比するかを示します。すべてのタスクで、オムニビジョンは以前の世界最小のビジョン言語モデルを凌駕しています。
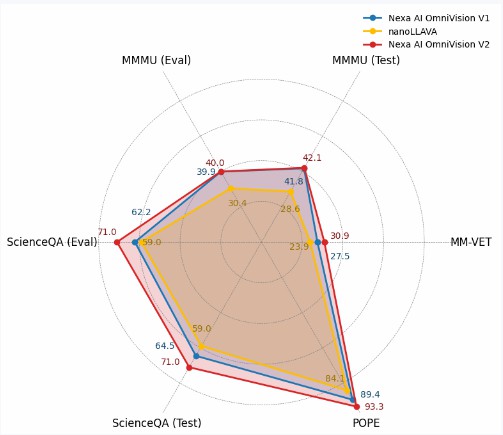
ベンチマークレーダーチャート
MM-VET、ChartQA、MMMU、ScienceQA、POPEなどのベンチマークデータセットでオムニビジョンの性能を評価するために、一連の実験を実施しました。
| ベンチマーク | Nexa AI Omnivision v2 | Nexa AI Omnivision v1 | nanoLLAVA |
|---|---|---|---|
| ScienceQA(評価) | 71.0 | 62.2 | 59.0 |
| ScienceQA(テスト) | 71.0 | 64.5 | 59.0 |
| POPE | 93.3 | 89.4 | 84.1 |
| MM-VET | 30.9 | 27.5 | 23.9 |
| ChartQA(テスト) | 61.9 | 59.2 | 未適用 |
| MMMU(テスト) | 42.1 | 41.8 | 28.6 |
| MMMU(評価) | 40.0 | 39.9 | 30.4 |
デバイス上で使用する方法
以下では、デバイス上でOmnivisionをローカルで実行する方法を示します。
ステップ1:Nexa-SDKをインストール(ローカルオンデバイス推論フレームワーク)
Nexa-SDKをインストール
Nexa-SDKは、テキスト生成、画像生成、ビジョン言語モデル(VLM)、音声言語モデル、音声認識(ASR)、テキストトゥスピーチ(TTS)機能をサポートするオープンソースのローカルオンデバイス推論フレームワークです。Pythonパッケージや実行可能インストーラーでインストール可能です。
ステップ2:ターミナルで以下のコードを実行
nexa run omnivision
モデルアーキテクチャ
オムニビジョンのアーキテクチャは、3つの主要なコンポーネントから成り立ちます:
ベース言語モデル:Qwen2.5-0.5B-Instructはテキスト入力を処理するベースモデルとして機能します ビジョンエンコーダ:SigLIP-400Mは384解像度で14×14のパッチサイズで画像埋め込みを生成します 投影層:マルチレイヤーパーセプトロン(MLP)は、ビジョンエンコーダの埋め込みを言語モデルのトークン空間に合わせます。標準のLlavaアーキテクチャと比較して、私たちは9X画像トークンを削減するプロジェクターを設計しました。 ビジョンエンコーダはまず入力画像を埋め込みに変換し、その後、投影層によってQwen2.5-0.5B-Instructのトークン空間に一致するように処理され、エンドツーエンドの視覚言語理解が可能になります。
トレーニング
私たちは3段階のトレーニングパイプラインを通じてオムニビジョンを開発しました:
プリトレーニング:初期段階では、画像キャプションペアを使用して基本的な視覚言語調整を確立し、投影層パラメーターのみをアンFREEZEしてこれらの基本的な関係を学習します。
監督ファインチューニング(SFT):画像に基づく質問応答データセットを使用して、モデルの文脈理解を強化します。この段階では、画像を組み込む構造化されたチャット履歴を用いてトレーニングを行います。これにより、モデルはより文脈に適した応答を生成できます。
ダイレクトバイアス最適化(DPO):最終段階では、まずベースモデルを使用して画像に対する応答を生成します。次に、教師モデルが最小限の編集で訂正を行い、オリジナル応答との意味的類似性を維持します。これは特に正確さが重要な要素に焦点を当てています。これらのオリジナルと訂正された出力を選んだ拒否ペアとします。このファインチューニングは、モデルのコア応答特性を変更せずに、本質的なモデル出力の改善を目指しています。
オムニビジョンの今後はどうなりますか?
オムニビジョンは初期開発段階であり、現在の制限に対処するために取り組んでいます:
DPOトレーニングの拡大:反復的なプロセスでDPO(ダイレクトバイアス最適化)トレーニングの範囲を拡大し、モデル性能と応答品質を継続的に改善します。 文書およびテキスト理解の改善 長期的には、オムニビジョンをエッジAIマルチモーダルアプリケーションのための完全に最適化された、プロダクション準備ができているソリューションとして開発することを目指しています。
aiスピーキング
ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?

