 ニュース
ニュース タイトル:DualPipe技術とマルチモーダルデータ処理の応用と最適化
aiスピーキング
ニュース  ニュース
ニュース  ニュース
ニュース  ニュース
ニュース  ニュース
ニュース  ニュース
ニュース 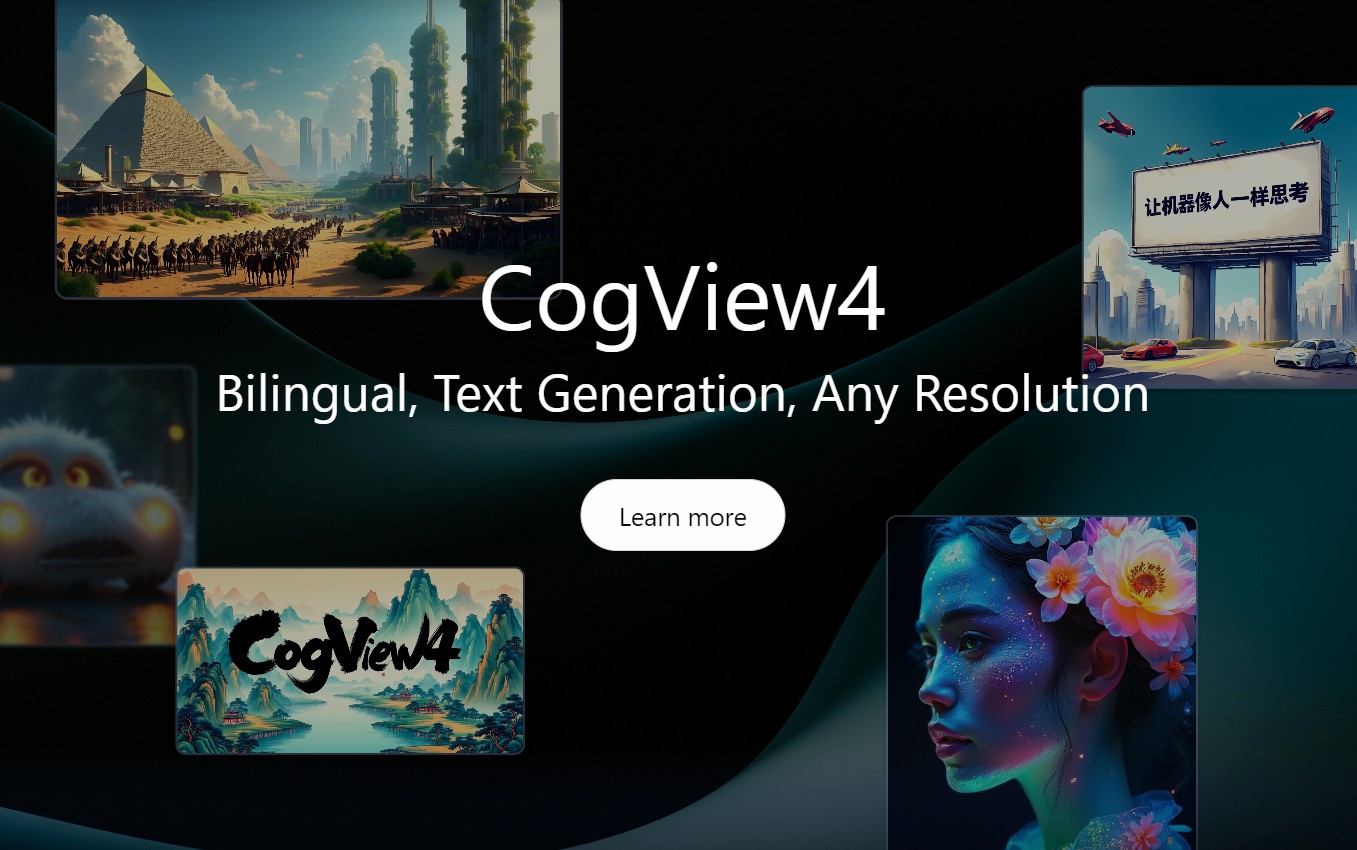 ニュース
ニュース  ニュース
ニュース  ニュース
ニュース  ニュース
ニュース