ASRとは何ですか?
ASR(Automatic Speech Recognition)は、人間の音声をテキストに変換する技術です。概念はシンプルですが、実際のアルゴリズムは比較的複雑で、実用化するにはさらに複雑になります。ASRの評価指標は一般的にWER(Words Error Rate)であり、一定の閾値を達成していないモデルはアプリケーションの場面がありません。
MMSpeechとは何ですか?
MMSpeechは、2022年12月に発表された、達摩院が開発した独自の音声プリトレーニングモデルです。OFAアーキテクチャに基づいており、無標識テキストを最大限に活用して、字間違い率を大幅に下げています。HuBertやWav2Vecなどの有名なモデルの中国語バージョンと比較して、標準的なベンチマークAIShell1の検証セット/テストセットでの字間違い率が48.3%/42.4%低下し、1.6%/1.9%に達し、SOTAの3.1%/3.3%を大幅に上回っています。
現在、4つのOFA-MMSpeechモデルがリリースされています。残りの3つは以下の通りです。
- プリトレーニングLargeモデル
- AIShell1ファインチューンBaseモデル
- AIShell1ファインチューンLargeモデル
方法の説明
MMSpeechは、中国語音声認識タスクに特化したプリトレーニング方法であり、大量の無標識の音声およびテキストデータを利用し、5つの音声/テキストタスクを統一されたエンコーダー-デコーダーモデルフレームワークの下でマルチタスク学習を行います。
これまでのプリトレーニング方法とは異なり、MMSpeechは2つの利点があります。一つは、無標識テキストデータ(合計292GB)を大幅に使用して、音声認識のプリトレーニング効果を向上させた点です。これは、テキストデータを使用しない音声単一モーダルプリトレーニング方法(Wav2Vec、HuBERT、Data2Vec、WavLMなど)とは異なり、またはテキストデータを少ない量(1.8GB)使用する音声-テキスト共同プリトレーニング方法(SpeechT5、STPT)とは異なります。私たちはテキストデータが音声認識プリトレーニングに与える価値を十分に探求し、大きな向上が見られることを証明しました。もう一方の利点は、MMSpeechは特に中国語音声シーンに特化したプリトレーニング方法である点です。これまでのプリトレーニング方法は主に英語データに基づいており、中国語と英語とは異なり、中国語は意図言語であり、音声とテキストモーダル間の違いがより大きくなります。これは、音声/テキストタスクが統一モデルを共有する際に困難をきたします。私たちは、音声とテキストを密接に結ぶモーダルである音素(phone、ここではピンインを使用)をプリトレーニングプロセスに導入し、音声とテキストモーダル間の違いの問題を緩和し、実験を通じてその導入がテキストデータをより大きな価値を発揮させ、プリトレーニング効果を向上させることを証明しました。
詳細については、論文の紹介を参照してください:https://arxiv.org/abs/2212.00500
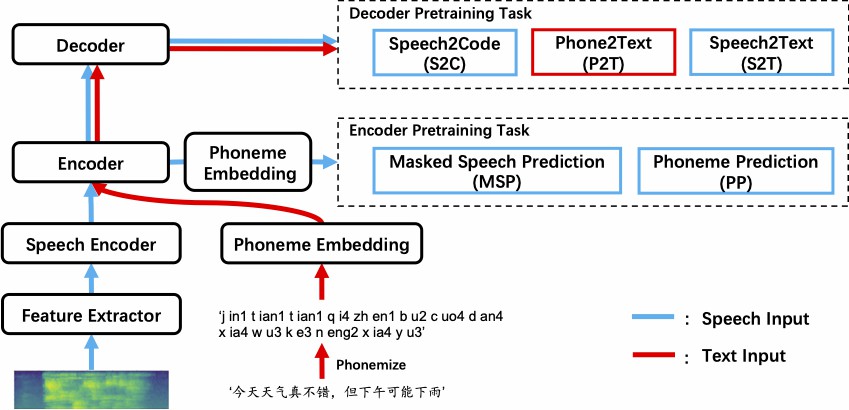
具体的には、MMSpeechのトレーニングプロセスは上記の図に示されているように、phone-to-text(P2T)、speech-to-code(S2C)、masked speech prediction(MSP)、phoneme prediction(PP)、speech-to-text(S2T)の5つのタスクから成ります。
その中では、phone-to-text、speech-to-codeの这2つのタスクはそれぞれ無標識のテキストデータおよび無標識の音声データを利用し、偽のペアデータを構築してエンコーダー-デコーダーに自監督学習を行わせるのに役立ちます。また、過去には多くのエンコーダーに対する音声プリトレーニングの方法(例えばWav2Vec)が無標識音声データでエンコーダーをトレーニングして良い音声表現を得ることができ、音声タスクの効果を向上させることが証明されていることから、MMSpeechではmasked speech prediction、phoneme predictionの这2つのタスクを導入し、無標識音声データを使用してエンコーダーのプリトレーニングを行います。最後に、私たちは音声認識タスクspeech-to-textもマルチタスク学習に導入し、モデルの効果をさらに向上させます。
関連するモデル
| モデル名 | モデルサイズ | 無標識音声 | 無標識テキスト | ラベル付き | プリトレーニング | ファインチューン |
|---|---|---|---|---|---|---|
| MMSpeech-Base | 210M | AIShell-2 | M6-Corpus | AIShell-1 | ofa_mmspeech_pretrain_base_zh | ofa_mmspeech_asr_aishell1_base_zh |
| MMSpeech-Large | 609M | WenetSpeech | M6-Corpus | AIShell-1 | ofa_mmspeech_pretrain_large_zh | ofa_mmspeech_asr_aishell1_large_zh |
Zero-shot && Finetune
Zero-shot MMSpeechでは、プリトレーニングプロセスで少量のダウンストリームASRタスクの標識データが導入され、ファインチューンなしでも良好な音声認識効果が得られますが、さらに良い効果を求める場合は次のセクションのファインチューンの例を参照してください。
プリトレーニングモデルを使用して直接推論を行うことができます。オーディオファイルを入力し、対象のテキストを出力します。モデルは任意のサンプリングレートおよびチャンネル数のWAVオーディオファイルをサポートし、推奨入力音声の長さは20秒以下です。
依存関係
pip install 'librosa<0.10.0'APIコールの例
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
pretrained_model = "damo/ofa_mmspeech_pretrain_base_zh"
pipe = pipeline(Tasks.auto_speech_recognition, model=pretrained_model, model_revision='v1.0.2')
result = pipe({"wav": "https://xingchen-data.oss-cn-zhangjiakou.aliyuncs.com/maas/speech/asr_example_ofa.wav"})
print(result) # 取引がほぼ停滞する状況も発生する可能性がありますFinetuneの例 現在のmodelscope==1.2.0以上のバージョンでは、pipelineとtrainの構成が一体化されており、ファインチューンプロセスを直接開始できます。
API使用例
import tempfile
from modelscope.msdatasets import MsDataset
from modelscope.metainfo import Trainers
from modelscope.trainers import build_trainer
from modelscope.utils.constant import DownloadMode
train_dataset = MsDataset(
MsDataset.load('speech_asr_aishell1_testsets', subset_name='default',namespace='modelscope', split='train').remap_columns({
'Audio:FILE': 'wav',
'Text:LABEL':'text'
}))
test_dataset = MsDataset(
MsDataset.load('speech_asr_aishell1_testsets', subset_name='default', namespace='modelscope', split='test').remap_columns({
'Audio:FILE': 'wav',
'Text:LABEL':'text'
}))
print(next(iter(test_dataset)))
def cfg_modify_fn(cfg):
cfg.train.hooks = [{
'type': 'CheckpointHook',
'interval': 2
}, {
'type': 'TextLoggerHook',
'interval': 1
}, {
'type': 'IterTimerHook'
}]
cfg.train.max_epochs=2
return cfg
args = dict(
model="damo/ofa_mmspeech_pretrain_base_zh",
model_revision='v1.0.2',
train_dataset=train_dataset,
eval_dataset=test_dataset,
cfg_modify_fn=cfg_modify_fn,
work_dir = tempfile.TemporaryDirectory().name)
trainer = build_trainer(name=Trainers.ofa, default_args=args)
trainer.train()データ評価および結果
AISHELL-1のdev/testデータセットでテストを行い、LMを加えていない効果
| モデル | dev(w/o LM) | dev(with LM) | テスト(w/o LM) | テスト(with LM) |
|---|---|---|---|---|
| MMSpeech-Base-Pretrain | 2.5 | 2.3 | 2.6 | 2.3 |
| MMSpeech-Base-aishell1 | 2.4 | 2.1 | 2.6 | 2.3 |
| MMSpeech-Large-Pretrain | 2.0 | 1.8 | 2.1 | 2.0 |
| MMSpeech-Large-aishell1 | 1.8 | 1.6 | 2.0 | 1.9 |
関連論文および引用 OFA-MMSpeechが役立ち、私たちの仕事を気に入っていただけた場合は、以下のように引用してください:
@article{zhou2022mmspeech, author = {Zhou, Xiaohuan and Wang, Jiaming and Cui, Zeyu and Zhang, Shiliang and Yan, Zhijie and Zhou, Jingren and Zhou, Chang}, title = {MMSpeech: 多モーダル多タスクエンコーダー-デコーダープリトレーニングによる音声認識}, journal = {arXiv preprint arXiv:2212.00500}, year = {2022} } @article{wang2022ofa, author = {Wang, Peng and Yang, An and Men, Rui and Lin, Junyang and Bai, Shuai and Li, Zhikang and Ma, Jianxin and Zhou, Chang and Zhou, Jingren and Yang, Hongxia}, title = {OFA: 単純なシーケンストゥシーケンス学習フレームワークを通じてアーキテクチャ、タスク、モーダルITYを統一する}, journal = {CoRR}, volume = {abs/2202.03052}, year = {2022} }
ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?

