昔から現在にかけて、人間は絶えず言語と音の可能性を探求し、掘り下げてきた。音声は最も直接的な人間のコミュニケーション手段として、常に技術革新の重要な分野となっている。近年はディープラーニング、ビッグデータなどの技術が急速に発展し、音声技術にはかつてない機会と課題が訪れている。特に2023年には、大規模モデルの広範な応用により、音声技術の研究と応用が大きな突破を遂げた。

大規模モデルの背景の下での音声技術の機会
音声認識と生成能力の向上
大規模モデルは、GPT-4などのように膨大な言語資料を学習し、高い正確性と流暢な音声体験をもたらす。これは、スマートフォンアシスタント、スマートホームデバイス、車載エンターテインメントシステムなどがより正確に音声コマンドを理解し、生成し、ユーザー体験を向上させることを意味する。
多言語と多模態性処理の実現
大規模モデルの応用により、音声技術は多言語と多模態性データの処理をよりよく行うことができる。例えば、同じ大規模モデルが中国語、英語など多言語を処理し、さらに画像、テキスト、音声など多模態性データを処理することができる。これは言語をまたぐ、文化をまたぐコミュニケーションが可能になり、企業にも多くのビジネスチャンスを提供する。

個人化と自己適応能力
大規模モデルは強力な学習と自己適応能力を持ち、ユーザーの言語習慣、アクセント、イントネーションなどに応じて自己調整し、より個人化された音声インタラクション体験を提供する。同時に、大規模モデルはユーザーの使用習慣とフィードバックに基づいて継続的に最適化し、音声技術の有用性と信頼性を高める。
大規模モデルの背景の下での音声技術の課題
データのセキュリティとプライバシーの問題
音声インタラクションが普及するにつれて、多くの音声データが収集され、分析される。これらのデータのセキュリティとプライバシー保護を確保することは重要な問題となっている。企業と研究機関は厳格なデータ暗号化と保護措置を講じ、データ漏洩と乱用を回避する必要がある。
データの不均衡な分布
大規模モデルは大規模なデータを処理することができるが、これらのデータはしばしば不均衡な分布を示している。特定のカテゴリーのデータは他のカテゴリーよりも豊富で、モデルがこれらのカテゴリーを処理する際の性能が向上する可能性がある。この問題を解決するためには、データ拡張、移行学習などの技術を用いてデータ分布をバランスさせる必要がある。
解釈可能性と堅牢性
大規模モデルは学習と生成能力が強力である一方で、その決定プロセスはしばしば解釈不可能である。これは人々がモデルの決定根拠とプロセスを理解するのが難しくなり、決定の不確実性を高める。また、モデルの堅牢性も課題である。音声インタラクション環境におけるノイズ、干渉、その他の要因がモデルの性能に影響を与える可能性がある。これらの問題を解決するためには、より解釈可能で堅牢なモデルと方法を研究する必要がある。

公正性と倫理性
大規模モデルのトレーニングと使用プロセスにおいても、公正性と倫理性の問題が存在する可能性がある。例えば、モデルのトレーニングデータに偏りがある場合、モデルは異なるグループの問題を処理する際に不公平さを示す可能性がある。さらに、音声技術への過度な依存は、人々に対面でのコミュニケーションの能力と機会を失わせることができる。したがって、音声技術を応用する際には、これらの倫理的および社会的な問題を考慮し、それらの問題を解決するための適切な措置と方法を講じる必要がある。
Dolphin AIの突破と革新
上記の課題に直面し、弊社は革新的な思考と先進技術をもって、第3世代の音声評価技術であるDolphin AIを打ち出した。この突破的な技術は大規模モデルフレームワークに基づいて、先進のディープラーニングアルゴリズムと大規模言語資料を使用し、より正確で迅速に音声品質を評価し、向上させることを目的とする。従来の音声評価技術と比較して、Dolphin AIは以下の優位性を持つ:
より高い正確性と信頼性
Dolphin AIは多言語をサポートし、基本および上級の問題に適しており、クラウドサーバーへの展開をサポートし、フレームワークがより統一されている。改善されたエンドツーエンドフレームワークにより、大規模な音声およびテキストデータの効果をよりよく発揮し、認識の正確性を向上させることができ、音素レベルでの正確性が25%以上向上している。ディープラーニングとビッグデータ解析を通じて、この技術はより正確に音声品質を評価し、誤判定と漏判定を減らすことができる。同時に、その内蔵された安定性と堅牢性により、環境ノイズおよびその他の干渉の影響を効果的に克服することができる。

より広範な応用シーン
個人ユーザーの音声トレーニングと向上、企業レベルの顧客サービス品質の最適化に関わらず、Dolphin AIは包括的な解決策を提供することができる。それは多言語処理をサポートするだけでなく、さまざまな分野とアプリケーションシーンにも適応することができる。エンドツーエンドフレームワークにより、計算メモリが約50%削減され、計算速度が約50%向上し、モバイル端末でも音素、単語、文、章などすべての基本問題を簡単にサポートすることができる。
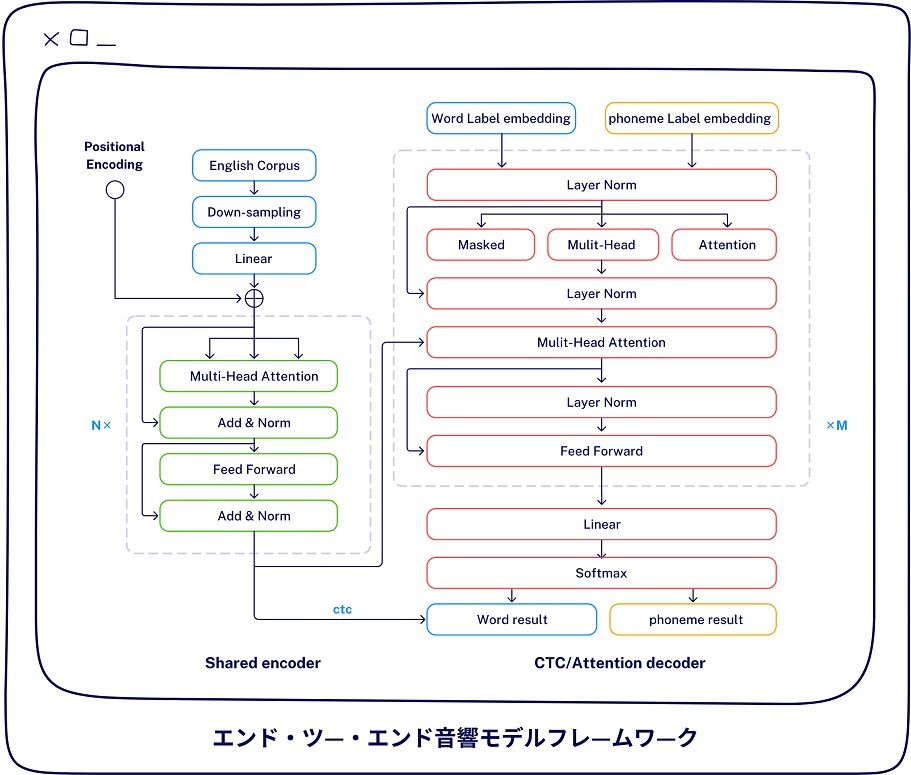
より強力な自己適応能力
Dolphin AIはユーザーの言語習慣、アクセント、イントネーションに応じて自己適応調整を行い、個人化された音声インタラクション体験を提供することができる。同時に、ユーザーフィードバックに基づいて継続的に最適化し、音声技術の有用性と信頼性を絶えず高める。プラットフォームはオンラインおよびオフラインでの呼び出しをサポートし、開発者が音声評価能力を迅速に統合できるように、Web API、およびAndroid、iOS、H5、C++などのプラットフォームSDKを提供する。
より高い効率と柔軟性
Dolphin AIは正確性と信頼性の突破だけでなく、処理速度と柔軟性においても優れている。それは大規模なデータセットを効率的に処理し、さまざまな異なるハードウェア環境に柔軟に適応することができる。データ拡張技術はノイズ、話速、エコー、音声振幅、クロスチャネルなど多角的な視点からトレーニングセットを数万時間に拡張し、モデルが変化する実際のシーンで依然として安定した効果を発揮し、モデルの堅牢性をさらに向上させ、より正確な評価スコアを得ることができる。
より強力な解釈可能性と倫理性
Dolphin AIは強力な学習と生成能力を提供するだけでなく、モデルの解釈可能性と倫理性にも重視している。透明な決定プロセスと公正なデータ使用方法を通じて、大規模モデルのトレーニングと使用プロセスにおける公正性と倫理性の問題を解決することを目指している。
将来の展望
2023年および今後の日々に、大規模モデルのさらなる発展と応用に伴い、音声技術分野でさらなる突破と革新が期待される。同時に、上記で述べた課題と問題に真摯に対処し、解決しなければならないことで、音声技術の健全で持続可能な発展を確保する必要がある。技術と社会の共通の推進の下で、音声技術が私たちの生活にさらなる驚きと可能性をもたらすと信じている。

