概要
Spark-TTSは、SparkAudioチームが開発した大規模言語モデル(LLM)に基づく効率的なテキスト読み上げ(TTS)ツールです。追加の生成モデルは不要で、LLMが予測したコードから直接音声を再構築し、ゼロショットテキストから音声への変換を実現します。Spark-TTSは中国語と英語の両方をサポートし、言語間の合成能力を持ち、性別、ピッチ、話す速度などのパラメーターを調整して仮想話者の声を生成し、多様なニーズを満たします。
主な機能
-
ゼロショットテキストから音声への変換:特定の音声データがなくても、話者の声を再現し、ゼロショット音声クローンを実現します。
-
マルチランゲージサポート:中国語と英語の両方をサポートし、言語間の音声合成を実現します。ユーザーは一種の言語でテキストを入力して、別の言語の音声出力を生成することができ、多言語環境下の音声合成ニーズを満たします。
-
制御可能な音声生成:ユーザーは性別、ピッチ、話す速度、音色などのパラメーターを調整して、仮想話者の声をカスタマイズし、特定のニーズに合った音声コンテンツを生成することができます。
-
効率的で簡潔な音声合成:Qwen2.5アーキテクチャに基づいており、流れのマッチングモデルなど追加の生成モデルは不要です。LLMが予測したコードから直接音声を再構築し、音声合成の効率を高めます。
-
仮想話者を作成する:ユーザーは完全に自分自身で定義する仮想話者を作成し、パラメーターを調整してユニークな音声スタイルを持たせることができます。これは、仮想キャスター、オーディオブックなどのシーンに適しています。
-
音声クローンとスタイルの移転:少量の音声サンプルからスタイルの特徴を抽出し、それを合成音声に移転することで、パーソナライズされた音声スタイルのコピーと移転を実現します。
技術原理
-
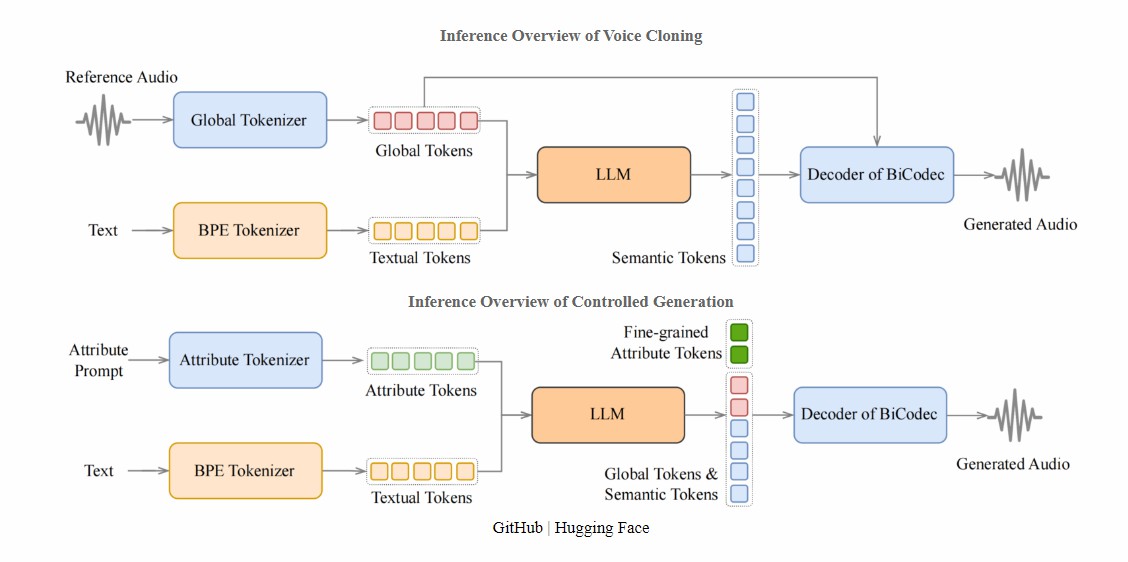
LLMに基づく効率的な音声合成:Spark-TTSは完全にQwen2.5アーキテクチャに基づいており、流のマッチングモデルなど追加の生成モデルが必要な従来のTTSの複雑なプロセスを排除します。LLMが予測したコードから直接音声を再構築し、音声合成のプロセスを単一流れで解離し、効率を高めます。
-
ゼロショット音声クローン:特定の話者のトレーニングデータがなくても、少量の音声サンプルからスタイルの特徴を抽出し、それを合成音声に移転することができます。
-
単一流れで音声コードを解離する:Spark-TTSは単一流れで音声コードを解離する技術を採用し、音声合成のフロントエンド(テキスト処理)とバックエンド(音声生成)を緊密に結合します。これにより、従来のTTSのフロントエンドとバックエンドが分離されていることによる複雑さを回避します。
プロジェクトアドレス
-
プロジェクトの公式ウェブサイト:https://sparkaudio.github.io/spark-tts/
-
Githubリポジトリ:https://github.com/SparkAudio/Spark-TTS
-
HuggingFaceモデルライブラリ:https://huggingface.co/SparkAudio/Spark-TTS-0.5B
アプリケーションシーン
-
音声アシスタントの開発:Spark-TTSは、音色、話す速度、ピッチなどのパラメーターを調整して、自然で流暢な音声出力を生成することができるため、パーソナライズされた音声アシスタントを開発するのに適しています。これにより、ユーザーにより人間的でパーソナライズされたインタラクションエクスペリエンスを提供することができます。
-
マルチランゲージコンテンツの制作:ツールは中国語と英語の両方をサポートし、言語間の音声合成を実現するため、異なる言語バージョン間で一貫した音声スタイルを維持する必要があるコンテンツクリエーターに適しています。例えば、マルチランゲージのオーディオブック、広告、教育資料の制作などです。
-
スマートカスタマーサービスと情報のアナウンスメント:Spark-TTSはテキスト情報を自然な音声に変換することができるため、スマートカスタマーサービスシステムに使用し、24時間の不间断サービスを提供することができます。また、公共交通機関、空港、病院などの公共の場所で情報のアナウンスメントを行うのにも適しています。
-
音声クローンと仮想キャラクターのボイスオーバー:Spark-TTSはゼロショット音声クローンをサポートし、特定の話者の音声スタイルを迅速にコピーすることができるため、仮想キャラクターのボイスオーバー、アニメーションの制作、仮想キャスターの分野などに適しています。
インストールと使用
インストール
-
クローンとインストール:
- リポジトリをクローンする:
git clone https://github.com/SparkAudio/Spark-TTS.git cd Spark-TTS - Conda環境をインストールする:
conda create -n sparktts -y python=3.12 conda activate sparktts pip install -r requirements.txt中国本土の場合、阿里云ミラーを使用することができます:
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
- リポジトリをクローンする:
-
モデルのダウンロード:
- Python経由でダウンロード:
from huggingface_hub import snapshot_download
snapshot_download("SparkAudio/Spark-TTS-0.5B", local_dir="pretrained_models/Spark-TTS-0.5B")
- git clone経由でダウンロード: ```bash mkdir -p pretrained_models git lfs install git clone https://huggingface.co/SparkAudio/Spark-TTS-0.5B pretrained_models/Spark-TTS-0.5B - Python経由でダウンロード:
基本的な使用法
-
コマンドラインでの推論:
python -m cli.inference \ --text "text to synthesis." \ --device 0 \ --save_dir "path/to/save/audio" \ --model_dir pretrained_models/Spark-TTS-0.5B \ --prompt_text "transcript of the prompt audio" \ --prompt_speech_path "path/to/prompt_audio" -
Web UIの使用:
- Web UIを起動する:
python webui.py --device 0 - Web UIは音声クローンと音声作成をサポートし、ユーザーはリファレンスオーディオをアップロードするか、直接オーディオを録音することができます。
- Web UIを起動する:
ランタイム環境
-
Nvidia Triton推論サービシ:
-
Spark-TTSは、Nvidia TritonとTensorRT-LLMを使用してデプロイするためのリファレンスを提供しています。単一のL20 GPU上で、26の異なるprompt_audio/target_textペア(合計169秒のオーディオ)を使用したベンチマーク結果は以下のとおりです: モデル ノート コンカレンシー 平均遅延 RTF Spark-TTS-0.5B コードコミット 1 876.24 ms 0.1362 Spark-TTS-0.5B コードコミット 2 920.97 ms 0.0737 Spark-TTS-0.5B コードコミット 4 1611.51 ms 0.0704 - 詳細なデプロイメント手順については、
runtime/triton_trtllm/README.mdを参照してください。
-
aiスピーキング
ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?