2025年3月25日、阿里巴巴(アリババ)は最新のマルチモーダル大規模モデル、Qwen2.5-VL-32Bをオープンソースで公開しました。このモデルは32Bのパラメーター規模でありながら、マルチモーダルタスクや純テキストタスクで優れた性能を発揮し、より大規模なQwen2-VL-72Bモデルを凌ぐ成果を収めました。これはマルチモーダルAI技術の大きな突破を示し、開発者や各業界に新たな機会をもたらしました。
モデル紹介
Qwen2.5-VL-32Bは、阿里巴巴(アリババ)がオープンソースで公開したマルチモーダルモデルで、強化学習を基に最適化され、人間の好みに合った回答スタイル、大幅に向上した数学的推理能力、そして画像の細かい理解と推理能力を持っています。このモデルはマルチモーダルタスク(MMMU、MMMU-Pro、MathVistaなど)と純テキストタスクの両方で優れた性能を発揮しています。

コア機能
-
画像理解と説明:画像の内容を解析し、物体やシーンを認識し、自然言語で説明を生成します。画像の内容の細かい分析、例えば物体の属性や位置などもサポートします。
-
数学的推理と論理分析:複雑な数学問題を解決し、幾何学や代数などに対応します。マルチステップの推理をサポートし、論理が明確で、整理が整っています。
-
テキスト生成と対話:入力されたテキストや画像に基づいて自然言語の回答を生成します。マルチラウンドの対話に対応し、文脈に応じて連続したコミュニケーションが可能です。
-
視覚質問応答:画像の内容に基づいて関連する質問に答えます。例えば物体の識別やシーンの説明など。複雑な視覚論理の導出、例えば物体間の関係の判断などもサポートします。
技術原理
-
マルチモーダル事前学習:大規模な画像とテキストデータを使用して事前学習を行い、豊富な視覚と言語の特徴を学びます。共有のエンコーダーとデコーダーの構造に基づいて、画像とテキストの情報を融合し、異なるモーダル間の理解と生成を実現します。
-
Transformerアーキテクチャ:Transformerアーキテクチャに基づいて、エンコーダーを使用して入力された画像とテキストを処理し、デコーダーがアウトプットを生成します。自己注意メカニズムに基づいて、モデルは入力の重要な部分に注目し、理解と生成の正確性を高めます。
-
強化学習最適化:人間によってアノテートされたデータとフィードバックに基づいて、モデルを強化学習で最適化し、人間の好みに合った回答を出力します。学習プロセス中には、回答の正確性、論理性、流暢性など、複数の目標を同時に最適化します。
-
視覚言語アライメント:対比学習とアライメントメカニズムを通じて、画像とテキストの特徴が意味空間でアライメントされ、マルチモーダルタスクの性能を高めます。
性能表現
-
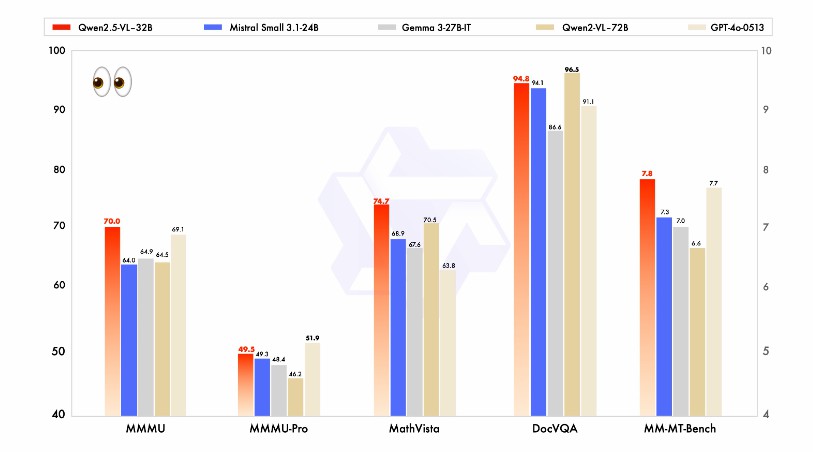
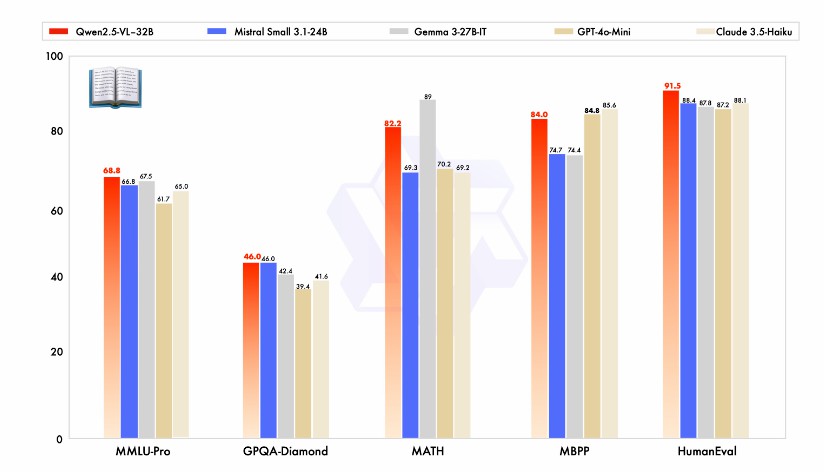
同規模モデル比較:Qwen2.5-VL-32Bは、Mistral-Small-3.1-24BやGemma-3-27B-ITよりも優れており、より大規模なQwen2-VL-72B-Instructモデルを凌ぐ性能を発揮します。
-
マルチモーダルタスクの表現:マルチモーダルタスクにおいて、例えばMMMU、MMMU-Pro、MathVistaなどでは、Qwen2.5-VL-32Bの表現が特に優れています。
-
MM-MT-Benchベンチマークテスト:前世代のQwen2-VL-72B-Instructと比較して、モデルは著しい進歩を収めました。
-
純テキスト能力:純テキストタスクにおいて、Qwen2.5-VL-32Bは同規模モデル中最適な性能を発揮しています。
アプリケーションシーン
-
スマートカスタマーサービス:テキストと画像の質問に正確な回答を提供し、カスタマーサービスの効率を向上させます。
-
教育支援:数学問題を解き、画像の内容を説明し、学習を支援します。
-
画像アノテーション:画像の説明とアノテーションを自動生成し、コンテンツ管理を支援します。
-
スマートドライブ:交通標識や道路状況を分析し、運転のアドバイスを提供します。
-
コンテンツクリエーション:画像に基づいてテキストを生成し、ビデオや広告の制作を支援します。
リソースリンク
- プロジェクトウェブサイト:https://qwenlm.github.io/zh/blog/qwen2.5-vl-32b/
- HuggingFaceモデルライブラリ:https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct
- オンラインデモデモ:https://chat.qwen.ai/
aiスピーキング
ドルフィンAIは言語学習アプリケーションのためのプロフェッショナルな発音評価API(pronunciation assessment api)ソリューションを提供します。音素、単語、文章、チャプター、発音矯正、単語矯正、クイズ、フリーダイアログ、多肢選択問題など幅広く提供しています。当社の発音評価製品(pronunciation assessment)は、英語と中国語、クラウドAPI、オンプレミス、オフラインデバイスの展開をサポートしています。当社の発音評価API(pronunciation assessment api)は、正確性、流暢性、完全性、リズムの次元をカバーする豊富な評価指標を提供し、音素、単語、文の異なるレベルの評価スコアも提供します。また、音素、単語、文の異なるレベルでの評価スコアも提供します。数千万人のユーザーに安定した効率的で安全なサービスを提供しています。ドルフィンAIの発音評価製品(pronunciation assessment)を試してみませんか?
